

决战性能之巅!NV双芯旗舰GTX590评测
10.4 统一寻址空间实现完全的C++支持
Fermi是第一个支持新并行线程执行(PTX)2.0指令集的体系结构。PTX是级别较低的虚拟机和ISA,目的是为了支持并行线程处理器的运作。在程序安装的时候,PTX指令会被GPU驱动转译成机器代码。
PTX的主要目标包括:
1. 提供一个能跨越数代GPU的稳定ISA
2. 让经过编译的应用程序充分利用GPU的性能
3. 提供一个支持 C、C++、Fortran以及其他编译器对象并且与机器无关的ISA
4. 为应用程序和中间件开发者提供一个代码分发ISA
5. 为优化映射PTX 代码至对象机器的代码产生器和转移器提供一个一般化的ISA
6. 让库以及性能核心程序(performance kernel)代码编写更容易
7. 提供一个可以跨越GPU内核规模(从几个到多个)的可伸缩编程模型
PTX2.0具备许多新的特性,大大提升了GPU(图形处理器)的可编程性、精度及性能。这些特性包括:完全的IEEE 32位浮点精度;所有变量和指针都有统一的寻址空间;64位寻址;以及针对OpenCL和DirectCompute的新指令。尤为重要的是,PTX2.0完全支持C++编程语言。
Fermi和PTX 2.0 ISA采用统一的寻址空间,将存取操作的三个不同的寻址空间(线程的私有局部空间、线程块的共用空间、全局空间)进行了统一。在PTX 1.0中,存取指令都具体对应这三个寻址空间中的一个,程序就可以在一个编译时确知的指定寻址空间中存取数值。这样很难为C和C++指针提供完全的支持,因为一个指针的目标寻址空间在编译时可能根本无从知晓而只有在运行时才能动态确定。
PTX 2.0把三个寻址空间都统一为一个单独、连续的寻址空间,因此只需一套存取指令,而不再需要三套针对不同寻址空间(局部的、共用的及全局存储器)的存取指令。统一寻址空间为40位,可以支持1 Terabyte的可设定地址的内存,而存取ISA支持64位以适应未来的增长。
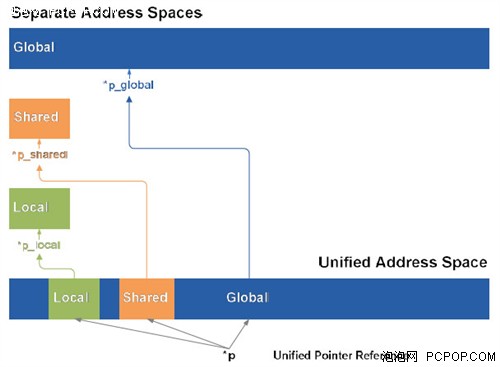
采用统一的寻址空间让Fermi可以真正支持C++程序。在C++中,所有的变量和函数都存在于对象中,而对象又通过指针进行传递。有了PTX 2.0,就可以利用统一的指针传递任意存储空间里的对象。Fermi的硬件地址转译单元自动将指针参考映射到正确的存储空间。
Fermi和PTX 2.0 ISA还支持C++虚拟函数、函数指针、针对动态对象分配、解除分配的“new”和“delete”操作以及针对异常处理的“try”和“catch” 操作。
● 针对OpenCL和DirectCompute的优化
OpenCL及DirectCompute同CUDA的编程模型有非常密切的对应关系,CUDA里的线程、线程块、线程块格、障栅同步、共用存储器、全局存储器以及原子操作都能在OpenCL和DirectCompute中看到,可以说OpenCL和DirectCompute的整个框架就是照搬CUDA的,因此基于CUDA的Fermi天生就已经为OpenCL和DirectCompute提供了优化。
此外,Fermi还为OpenCL和DirectCompute的表面(surface)格式转换指令提供了硬件支持,允许图形与计算程序能简单地对相同的数据进行操作。PTX 2.0 ISA还为DirectCompute提供了population count、append以及bit-reverse 指令的支持。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

