

泰坦的孪生兄弟!NVIDIA GTX 780首测
Kepler GK110 中的新功能,如 CUDA 内核能够利用 Dynamic Parallelism 在 GPU 上直接启动工作,需要 Kepler 中 CPU‐to‐GPU 工作流提供比 Fermi 设计增强的功能。Fermi中,线程块的Grid可由CPU启动,并将一直运行到完成,通过 CUDA Work Distributor (CWD) 单元创建从主机到SM的简单单向工作流。Kepler GK110目的是通过GPU有效管理CPU和CUDA创建的工作负载来改进 CPU‐到‐GPU 的工作流。
我们讨论了 Kepler GK110 GPU 允许内核直接在GPU上启动工作的能力,重要的是要理解在Kepler GK110 架构所做的变化,促成了这些新功能。Kepler 中,Grid 可从 CPU 启动,就和Fermi 的情况一样,但是新 Grid 还可通过编程由 CUDA 在 Kepler SMX 单元中创建。要管理CUDA 创建的 Grid 和主机生成的 Grid,在 Kepler GK110 中引入新 Grid Management Unit (GMU)。该控制单元管理并优先化传送到 CWD 要发送到 SMX 单元执行的 Grid。
Kepler 中的 CWD 保留准备好调度的 Grid,并能调度 32 个活动的 Grid,这是 Fermi CWD 容量的两倍。Kepler CWD 通过双向链接进行通信,允许 GMU 暂停新 Grid 的调度并保留挂起和暂停的 Grid,直到需要。GMU 也有到 Kepler SMX 单元的直接连接,允许 Grid 通过 Dynamic Parallelism 在 GPU 上启动其他工作,以将新工作传回到 GMU 进行优先化和调度。如果暂停调度的额外工作量的内核,GMU 将保持其为不活动,知道以来工作完成。
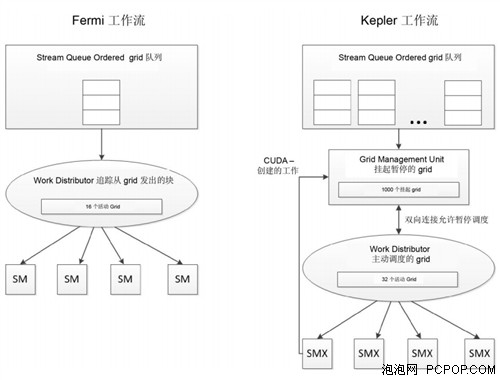
重新设计的 Kepler HOST 到 GPU 的工作流显示新 Grid Management Unit,允许其管理主动调度的 Grid、暂停调度、保留挂起和暂停的 Grid。
NVIDIA GPUDirect
当处理大量的数据时,提高数据吞吐量并降低延迟,对于提高计算性能是至关重要的。Kepler GK110 支持NVIDIA GPUDirect 中的 RDMA,目的是通过允许第三方设备,如 IB 适配器、NIC 和 SSD,直接访问 GPU 内存‐来提高性能。使用 CUDA 5.0 时,GPUDirect 提供以下重要功能:
无需 CPU方面的数据缓冲, NIC 和 GPU 之间的直接内存存取 (DMA)
显著改善 GPU和其他网络节点之间的 MPISend/ MPIRecv 效率。
消除了 CPU 带宽和延迟的瓶颈
与各种第三方网络、捕获和存储设备一起工作
如逆时偏移(用于石油和天然气勘探地震成像)这样的应用程序,将大量影像数据分布在多个GPU。数以百计的 GPU 必须合作,以紧缩的数据,经常通信中间结果 GPUDirect 利用 P2P 和RDMA 功能为服务器内或服务器之间“ GPU‐ 到‐GPU” 的通信的情况分配更高的总带宽。
Kepler GK110 还支持其他功能 GPUDirect,如 Peer‐to‐Peer 和 GPUDirect for Video。
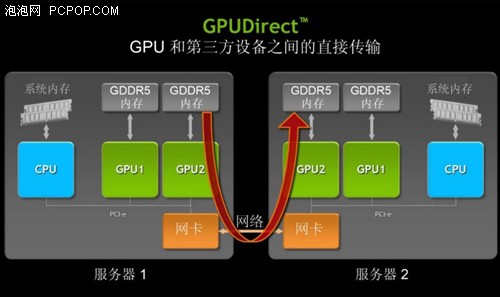
GPUDirect RDMA 允许网络适配器这样的第三方设备访问GPU内存,转换为跨节点GPU之间直接传输。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

