

泰坦的孪生兄弟!NVIDIA GTX 780首测
新ISA编码:每个线程255个寄存器
可由线程访问的寄存器的数量在 GK110 中已经翻了两番,允许线程最多访问 255 个寄存器。由于增加了每个线程可用的寄存器数量,Fermi 中承受很大寄存器压力或泄露行为的代码的速度能大大的提高。典型的例子是在 QUDA 库中使用 CUDA 执行格点 QCD(量子色动力学)计算。基于 QUDA fp64 的算法由于能够让每个线程使用更多寄存器并减少的本地内存泄漏,所以其性能提高了 5.3 倍。
Shuffle 指令
为了进一步提高性能,Kepler 采用 Shuffle 指令,它允许线程在 Warp 中共享数据。此前,Warp 内线程之间的数据共享需要存储和加载操作以通过共享内存传递数据。使用 Shuffle 指令,Warp 可以读取来自Warp 内其他线程中任意排列的值。Shuffle 支持任意索引引用(即任何线程读取任何其他线程)。有用的 Shuffle 子集包括下一线程(由固定量弥补抵消)和 Warp 中线程间 XOR “蝴蝶”式排列,也称为 CUDA 性。
Shuffle 性能优于共享内存,因此存储和加载操作能够一步完成。Shuffle 也可以减少每个线程块所需共享内存的数量,因为数据在 Warp 级交换也不需要放置在共享内存中。在 FFT 的情况下,需要共享一个 Warp 内的数据,通过使用 Shuffle 获得 6%的性能增益。
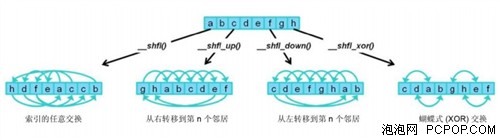
此示例表明某些变量可以在 Kepler 中使用 Shuffle 指令。
原子运算
原子内存运算对并行编程十分重要,允许并发线程对共享数据结构执行正确的读‐修改‐写运算。原子运算如 add、min、max 和 compare,swap 在某种意义上也是也是原子运算,如果在没有其他线程干扰的情况下执行读、修改和写运算。原子内存运算被广泛用于并行排序、归约运算、建制数据结构而同时不需要锁定线程顺序执行。
Kepler GK110 全局内存原子运算的吞吐量较 Fermi 时代有大幅的提高。普通全局内存地址的原子运算吞吐量相对于每频率一个运算来说提高了 9 倍。独立的全局地址的原子运算的吞吐量也明显加快,而且处理地址冲突的逻辑已经变得更有效。原子运算通常可以按照类似全局负载运算的速度进行处理。此速度的提高使得原子运算足够快得在内核内部循环中使用,消除之前一些算法整合结
果所需要的单独的归约传递。Kepler GK110 还扩展了对全局内存中 64‐位原子运算的本机支持。除了 atomicAdd、atomicCAS 和 atomicExch(也受 Fermi 和 Kepler GK104 支持)之外,GK110 还支持以下功能:
atomicMin、atomicMax、atomicAnd、atomicOr、atomicXor
其他不受本机支持的原子运算(例如 64 位浮点原子运算)可以使用 compare‐and‐swap (CAS) 指令模拟。
纹理改进
GPU 的专用硬件纹理单元对于需要取样或过滤图像数据的计算机程序来说是宝贵的资源。Kepler中的纹理吞吐量与 Fermi 相比有明显提高,每个SMX单元包含16纹理过滤单元,对比Fermi GF110 SM 提高了4倍。
此外,Kepler改变了管理纹理状态的方法。在Fermi时代,为让GPU引用纹理,必须在固定大小绑定表中分配“槽”才能启动 Grid。表中槽数量最终限制程序一次可以读取多少个独特的纹理。最终,在 Fermi 中限制程序仅可以同时访问128纹理。
Kepler中有无绑定纹理,不需要额外步骤:纹理状态已保存为内存中的对象,硬件按需获取这些状态对象,绑定表过时。这有效地消除了计算程序引用独特纹理数量的任何限制。相反,程序可以在任何时间映射纹理和通纹理处理周围。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

