

泰坦的孪生兄弟!NVIDIA GTX 780首测
在混合 CPU‐GPU 系统中,由于 GPU 的性能/ 功率比提高,使应用程序中大量并行代码完全在GPU 高效运行,提高了可扩展性和性能。为了加快应用程序的额外并行部分的处理,GPU必须支持更加多样化的并行工作负载类型。
Dynamic Parallelism 是 Kepler GK110 引入的新功能,能够让 GPU 在无需 CPU 介入的情况下,通过专用加速硬件路径为自己创造新的工作,对结果同步,并控制这项工作的调度。
在内核启动时,如果问题的规模和参数已知,那么 Fermi 在处理大型并行数据结构时效果非常好。所有的工作是从主机 CPU 启动,会运行到完成,并返回结果返回到 CPU。结果将被用来作为最终的解决方案的一部分,或通过 CPU 进行分析,然后向 GPU 发送额外的处理请求以进行额外处理。
在 Kepler GK110中,任何一个内核都可以启动另一个内核,并创建处理额外的工作所需的必要流程、事件以及管理依赖,而无需主机 CPU 的介入。T 该架构能让开发人员更容易创建和优化递归和数据依赖的执行模式,并允许更多的程序直接运行在 GPU 上。可以为其他任务释放系统CPU,或可以用功能少的 CPU 配置系统以运行相同的工作负载。
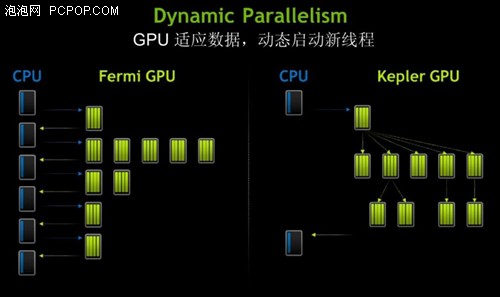
Dynamic Parallelism 允许应用程序中更多的并行代码直接由 GPU 本身启动(右侧图像),而不需要 CPU 的干预(左侧图像)。
Dynamic Parallelism 允许更多种并行算法在 GPU 上执行,包括不同数量的并行嵌套循环、串行控制任务线程的并行队或或卸载到 GPU 的简单的串行控制代码,以便促进应用程序的并行部分的数据局部化。
因为内核能够根据GPU 中间结果启动额外工作负载,程序员现在可以智能处理负载平衡的工作,以集中其大量资源在需要处理能力最大或与解决方案最有关的问题上。
一个例子是动态设置数值模拟的 Grid。 通常 Grid 主要集中在变化最大的地区,需要通过数据进行昂贵的前处理。另外,均匀粗 Grid 可以用来防止浪费的 GPU 资源,或均匀细 Grid 可以用来确保捕获所有功能,但这些选项的风险是在不太被注意的地区缺少模拟功能或“过度消费”的计算资源。
有了 Dynamic Parallelism,可以在运行时以数据依赖形式动态确定‐Grid解决方案。以粗 Grid开始,模拟“放大”注意的区域,同时避免在变化不大区域中不必要的计算。虽然这可以通过使用一系列的 CPU 启动的内核来完成,但是通过分析数据、作为单个模拟内核部分启动额外工作让 GPU 细化 Grid 本身要简单的多,消除了 CPU 的中断以及CPU和GPU之间的数据传输。
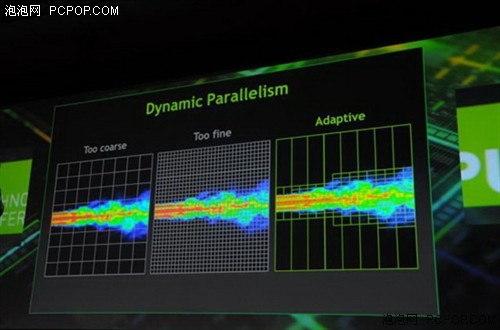
上面的例子说明了在数值模拟,采用动态调整 Grid 的好处。为了满足峰值的精度要求,固定的分辨率仿真必须运行在整个模拟域过于精细的分辨率上,而多分辨率 Grid 根据当地的变化为每个区域应用正确的模拟分辨率。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

