

打倒X86!NVIDIA的CPU+GPU战略全解析
分享
不过GPU的发展也会受到阿姆达尔定律的影响,当GPU集成的核心数量越来越多时也一定会遇到瓶颈。解决瓶颈的方法可以是在GPU中加入线程控制机能,用来安排指令优先级和打包指令使其提高执行效率。
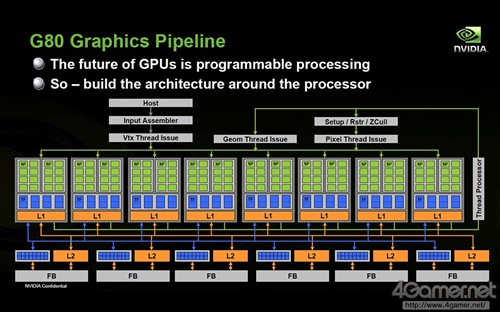
NVIDIA G80核心流水线示意图

NVIDIA GT100(GTX280)核心架构图
NVIDIA在G80架构中首次在芯片和流处理器(SM)级别都加入了线程管理机能"Thread Scheduler",此后随着图形核心的发展,在Fermi架构上Thread Scheduler进化为"Gigathread Engine",使得并行运算性能进一步得到大幅提高。
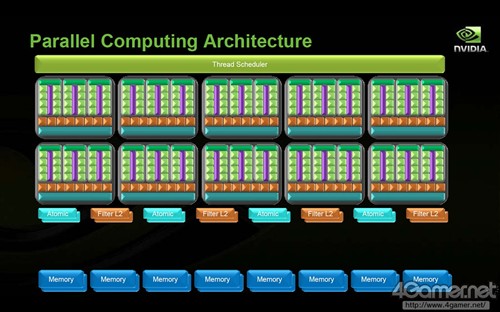
并行计算架构示意图

Fermi核心架构图,Thread Scheduler进化为GigaThread Engine
但是,在CUDA Core数量最大已经达到512个的况下,如果再增加势必会给线程管理模块部分带来更高负荷,甚至有发热过高烧毁的危险。因此,为了使GPU的并行计算性能维持优势,需要搭载更加强力的线程控制及管理模块,Project Denver正是为此诞生。
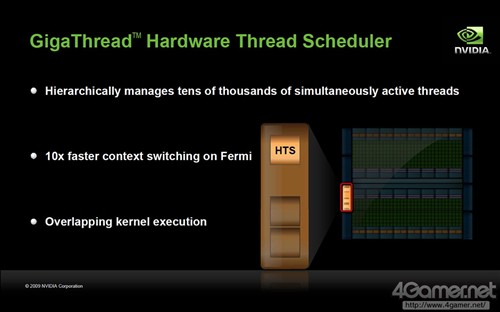
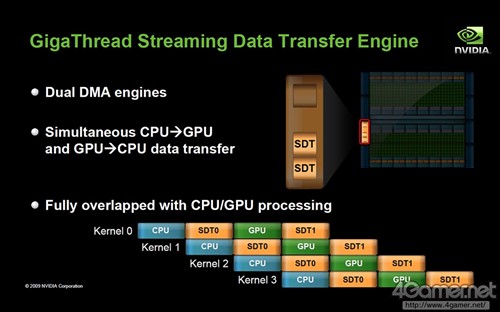
GigaThread Engine介绍,搭载2基硬件级别线程管理DMA引擎
NVIDIA负责产品市场部门的执行副总裁Ujesh Desai确认了Project Denver从三年前就已经开始开发,目标是实现CPU和GPU的统合。
0人已赞
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}
违法和不良信息举报电话:010-59548436,010-59544810,17352615567,17816876620,niuxiaotong@pcpop.com,jiachanjuan@126.com

