

打倒X86!NVIDIA的CPU+GPU战略全解析
2011年7月下旬在东京六本木举行的GTC Workshop Japan 2011大会上,NVIDIA日本分公司的馬路徹做了名为GPU架构和GPU计算入门的演讲,其中说明了GPU计算能力的现状。

他在演讲中提到:受益于18个月晶体管集成度提高一倍的摩尔定律,CPU的性能在2000年以前顺利提升。2000年之前,平均每年晶体管的速度随着工艺进步提高约19%,Pipeline-F/F(即Flip-Flop,触发器,具有记忆功能短暂保存输入信号的逻辑回路)之间的逻辑门数目每年削减约9%,微架构带来的性能改良每年约18%,总体计算每年CPU提高的性能约(1.19*1.09*1.18-1)*100%=52%。
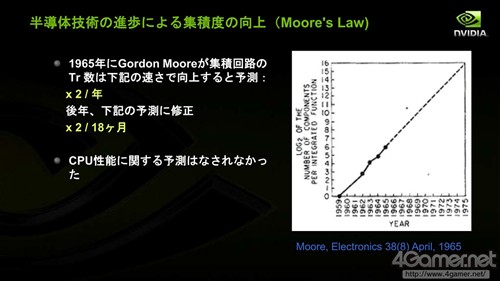
摩尔定律其实不是预测CPU性能提高的规律
而是预测半导体技术提高幅度的规律,主要是晶体管的集成度
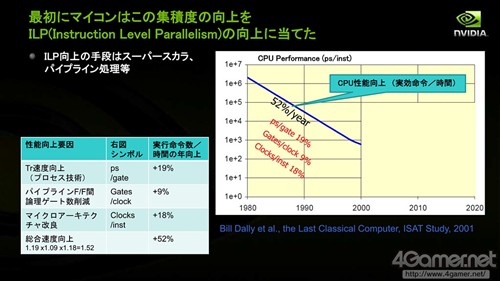
2000年前,CPU性能基本按照摩尔定律所预测的幅度逐年提高性能
但是在2000年以后,尤其CPU开始受益于多核化的2005年以后,摩尔定律逐渐遇到瓶颈,而和多核处理器并行计算性能有关的阿姆达尔定律(Amdahl''s Law)逐渐受到关注。
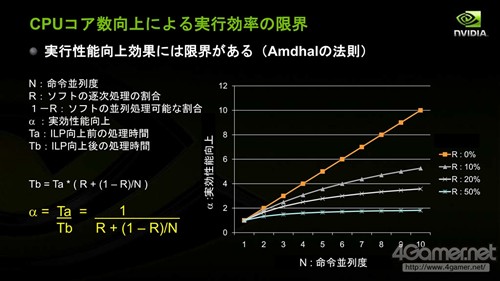
阿姆达尔定律:单纯靠CPU核心数提高改进执行效率是有界限的
阿姆达尔定律的准确内容是:固定负载(计算总量不变时),计算机的加速比可用(Ws+Wp)/(Ws+Wp/p)来表示,其中Ws,Wp分别表示问题规模的串行分量(问题中不能并行化的部分)和并行分量,p表示处理器数量。对该式取极限即当处理器数量接近无穷大时,结果为1+Wp/Ws,也就是无论我们如何增大处理器数目,加速比无法高于(据维基百科)。

2000年后CPU堆积晶体管的方式转为提高核心数量
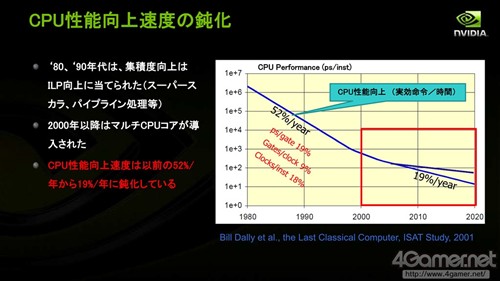
CPU性能提高的速度在逐年放缓
当然,CPU厂商已经预计到阿姆达尔定律所预见的情况出现,将CPU改造成适合并行计算的架构和加入对应的指令集。Intel的MMX,SSD,AVX等强化SIMD计算功能的指令集就是如此;同时Intel还推出了一系列对应多核CPU的开发套件,均为了提高并行计算性能。
不过,这种手段也有界限,最终结果就是,HPC等高性能计算业界纷纷转向原本就拥有适合提高并行计算性能架构的GPU。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

