

CPU大势已去!CUDA2.0演绎GPU超强实力
今年,NVIDIA丢出了一颗核弹——全新的GTX200核心,这是NVIDIA蓄谋已久的秘密武器。与G8X和G9X这些核心相比,GT200算是革命性的改进,但是这样一个强大的武器在遇到HD4800的时候并没有压倒性的优势,似乎并非一个拥有2倍于G80、14亿晶体管的怪兽所该有的实力。

看样子我们不得不去问问NVIDIA是否不在乎GPU的3D性能了,当然,这只是个玩笑罢了,开发如此旗舰级的GPU是需要准备很长时间的,我们没理由去猜测NV会拿整个市场来赌博。因此,对于GeForce 200GTX的性能表现,只能总结为低估了对手,有点傲慢和自大了。
反过来想想,如果NVIDIA开发了一个小巧的核心、但却拥有强大3D性能的GT200,是否就是正确的呢?这可就难说了,我们有理由相信,NVIDIA的目光已不再局限在目前的3D图形领域了,GTX200的架构更多的是为通用计算进行优化,从而提供比G8X/G9X更高的非图形运算效能。相比之下3D性能的提升只要就靠堆流处理器来实现了。

对于GT200的结构之前就介绍了不少,有兴趣的读者可以看看我们之前的评测,这里就不再赘述。正是由于GT200相当复杂的内部结构,使得计算能力得到了很大的提升。在频率保持和G80不变的情况下,性能比G92提升了50%以上。
由于核心结构的重大改变,虽然性能的提升并没有达到我们想象的高度,但是GPU却更适应未来的要求,无论在何种测试下,GT200都达到了前所未有的成绩。
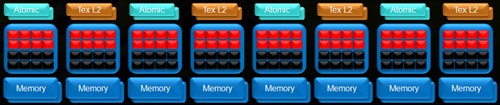
GTX200核心的8个ROPs和8个64Bit显存控制器
G8x和G9x的显存规格上,每一块都是64或者128字节,而且非常严格。从GPU开始计算的时候,整个16个线程都会参与,如果每个线程都需要一个32位的数据,那么将会分配到64字节的空间,看起来相当不错的一个管理模式其实存在很大的问题。浅显的说就是当全部线程一起发出的时候整个带宽会明显不足,但实际上根本没有占用那么多。
而GT200的显存控制器经过修正和改良,使得控制相当有效,位宽也被加大到了512,当需要存取64或者128字节的时候,也许只包含了32字节的数据,这时就会启用非时序模式,这个模式具有非连续和不排列的特点,这样就不会增加太多的占用,达到控制更有效的目的。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}