

CPU大势已去!CUDA2.0演绎GPU超强实力
第一次详细谈及CUDA恐怕是在一年前了,一年的时间让CUDA从默默无闻到逐渐发展壮大,使用者与日俱增并有望成为业界新的标准,CUDA有何魅力引无数程序员竟折腰?相信很多朋友对此都饶有兴趣。现在我们就通过NVIDIA法国分公司与Hardware.fr网站一次关于CUDA 2.0的讨论会的记录来看看,NVIDIA在一年的时间内是如何修正和改进新CUDA的。

如果没记错的话,NVIDIA是从GeForce 8系列开始同步开发了CUDA,而开发的接口和语言都是源自于C语言,只有这样才能挖掘出GPU强大的运算能力和多任务性。但是有一点还是不一样,在上个系列中,GPU不像CPU一样能适应高速处理,这导致了想让GPU正常工作还得选择合适的任务它才能处理。

实际上,GPU的目的并不是取代CPU,而是帮助它处理一些任务,换句话说,GPU就像一个协处理器,CPU的伙伴一样。NVIDIA也同样考虑过如果GPU太强大的话势必对CPU造成一种威胁,使得两者之间不是合作而是竞争,毕竟物竞天择,适者生存,落后肯定要被淘汰,于是NVIDIA也就一直在为提高GPU的性能和扩展功能而努力!

去年,NVIDIA推出了一块强有力的芯片——Tesla,它的出现给整个业界一个注入了一济强心针。这块基于G80核心的显卡每个GPU拥有高达1.5G的显存,比起当时的768MB的GeForce 8800GTX确实是个怪物,而这个怪物没有视频输出接口。当时NV总共展出了3块这样的卡,这是NV给世人展示自己实力的一个机会。
也许Tesla 和GeForce最大的不同就在价格,当大家意识到普通GeForce游戏显卡也能支持CUDA运算的话,那么Tesla的诱惑力就不是那么大了。好在NVIDIA及时地将工作重心转移到了CUDA软件发展上面,便宜的GeForce反而能够更有效的推广CUDA应用,这是一个新标准出台时必备的基础。
今年,NVIDIA丢出了一颗核弹——全新的GTX200核心,这是NVIDIA蓄谋已久的秘密武器。与G8X和G9X这些核心相比,GT200算是革命性的改进,但是这样一个强大的武器在遇到HD4800的时候并没有压倒性的优势,似乎并非一个拥有2倍于G80、14亿晶体管的怪兽所该有的实力。

看样子我们不得不去问问NVIDIA是否不在乎GPU的3D性能了,当然,这只是个玩笑罢了,开发如此旗舰级的GPU是需要准备很长时间的,我们没理由去猜测NV会拿整个市场来赌博。因此,对于GeForce 200GTX的性能表现,只能总结为低估了对手,有点傲慢和自大了。
反过来想想,如果NVIDIA开发了一个小巧的核心、但却拥有强大3D性能的GT200,是否就是正确的呢?这可就难说了,我们有理由相信,NVIDIA的目光已不再局限在目前的3D图形领域了,GTX200的架构更多的是为通用计算进行优化,从而提供比G8X/G9X更高的非图形运算效能。相比之下3D性能的提升只要就靠堆流处理器来实现了。

对于GT200的结构之前就介绍了不少,有兴趣的读者可以看看我们之前的评测,这里就不再赘述。正是由于GT200相当复杂的内部结构,使得计算能力得到了很大的提升。在频率保持和G80不变的情况下,性能比G92提升了50%以上。
由于核心结构的重大改变,虽然性能的提升并没有达到我们想象的高度,但是GPU却更适应未来的要求,无论在何种测试下,GT200都达到了前所未有的成绩。
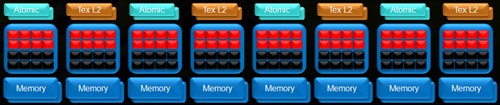
GTX200核心的8个ROPs和8个64Bit显存控制器
G8x和G9x的显存规格上,每一块都是64或者128字节,而且非常严格。从GPU开始计算的时候,整个16个线程都会参与,如果每个线程都需要一个32位的数据,那么将会分配到64字节的空间,看起来相当不错的一个管理模式其实存在很大的问题。浅显的说就是当全部线程一起发出的时候整个带宽会明显不足,但实际上根本没有占用那么多。
而GT200的显存控制器经过修正和改良,使得控制相当有效,位宽也被加大到了512,当需要存取64或者128字节的时候,也许只包含了32字节的数据,这时就会启用非时序模式,这个模式具有非连续和不排列的特点,这样就不会增加太多的占用,达到控制更有效的目的。
可能之前大家也注意到了。G9X芯片已经引入了一种更有效的方法使得CPU和GPU能协调工作,但是使用的是先把数据传给GPU再传给CPU的工作方式,这是G8X做不到的。而到了GT200。更是加强了这方面,据NVIDIA表示,明年的下一代产品将能够同时接收和发送数据到两个核心,使得CPU和GPU数据同步。
GT200的一个新功能就是GPU运算,因此,GT200也可以用于双精度64位浮点运算,而这项技术源自于多重处理器的专用单元。
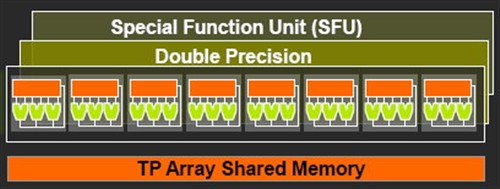
每一个多重处理器都包含了8个主要的FMAD处理器和8和MUL处理器来实现一些特殊功能的计算等,这样,一个64位的FMAD处理器就产生了。但是这样的处理器对于64位的计算能力相当低下,8X的低速FMAD和16X的低速FMUL都是导致计算能力低下的原因。
这个支持64位也意味着可以以它为模板为将来的更高级和新一代的GPU发展提供代码或者应用程序的支持,从而得到更好的甚至超过一个以上的64位处理器。每一个多重处理器都具有两个流处理线,这样就不必依赖周期而同时处理两个信号。
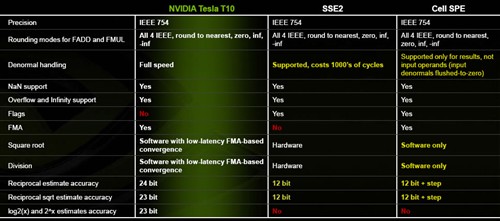
8 FMAD 32 bits + 8 FMUL 32 bits
8 FMAD 32 bits + 2 special features 32-bit
8 FMAD 32 bits + 1 FMAD 64 bits
1 FMAD 64 bits + 2 special features 32-bit
GTX200核心的每一个SM都包括了一个双精度64Bit浮点运算单元,这样GTX200就相当于一个30核心的双精度64Bit处理器,但GPU的频率要比CPU低很多,因此GTX200的理论64Bit浮点运算能力大概与Intel优异八核心至强处理器相当。
双精度的运算量是单精度的八倍,因此理论浮点运算能力只有原来的1/8,GTX280的双精度64Bit浮点运算能力大概在90GFLOPS左右。
CUDA是NVIDIA开发的一个运算平台(开发环境),工具集的核心是一个C语言编译器,其中包括一些扩展C语言,开发库,一个编译器和一个试点。 CUDA要求开发者组织好整个都是由GPU的模块线程所完成的工作,每个模块可能含有多达512个线程,而这些模块又会在一个多重处理器里同时被激活参与运算。
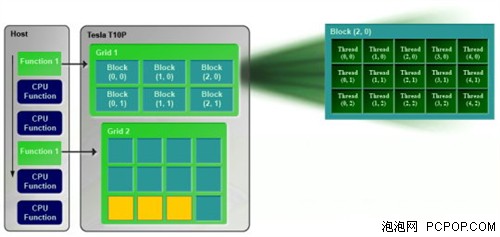
由于同一个模块里每个线程之间可以互相通信,因此它们共享16KB的缓存,而这16个区块之间也存在着联系,他们被强制使用全速存取,同时还要避免一个线程的数据全部传到另一个线程里,这也是CUDA很重要的一部分。

而往往正是上面的问题,开发者必须好好组织线程,因此NVIDIA在开发过程中不断尝试加大每个多重处理器的线程和共享内存的大小。
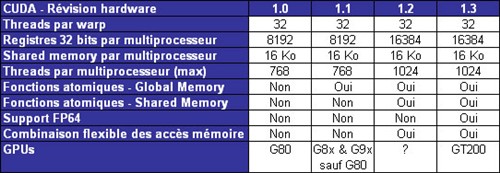
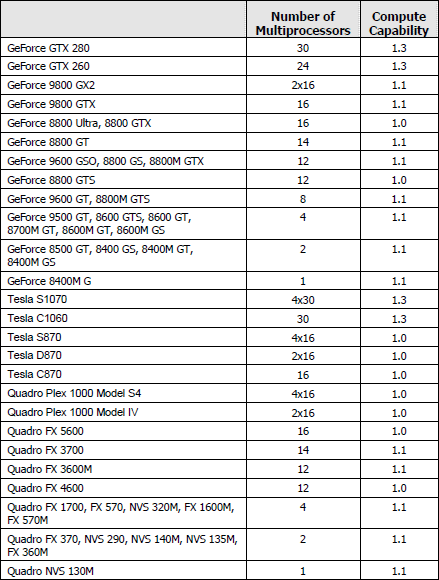
随着GT200的上市,CUDA 2.0也被正式的提出,虽然目前还是测试版本,打新的开发环境必然有新的特点,相对之前的,GT200包含了多种特性。
- CUDA 2.0和多核X86
当然,这才是我们这次最重要的部分:为多核X86 CPU添加一个CUDA编译器进行优化。
目前的CUDA所用的运算方法是分开的,一部分由CPU负责,而另一部分通过CUDA编译器使用GPU进行运算。在CUDA 2.0内,可以将GPU负责的部分也交由CPU进行运算,这样将能够彻底利用上未来的多核CPU能力。
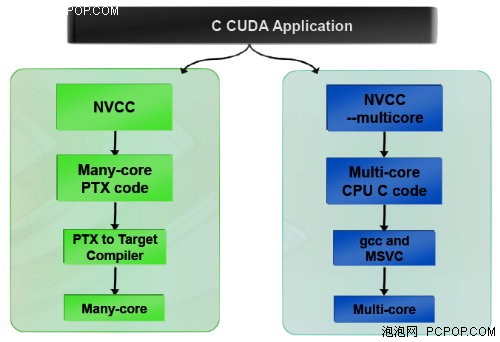
近期内会有一个针对CUDA 2.0的测试版出现,虽然目前还不知道其真正的水平,但看起来非常不错。新的计划,新的定位,不知道NVIDIA到底在想什么。虽然现在GPU和CPU的大战中GPU超出的部分太多,特别是有CUDA助阵,但想到不久的将来,Larrabee上市之后呢?整个情况又会发生什么样的变化,Intel为Larrabee配备了至少32个内核,加上和自家CPU的配合,不知道CUDA还有多大优势。
- Tesla Series 10
上个月NV刚公布了基于GT200的Tesla 2的新品,正如我们所猜测的,NVIDIA已改变了主意,凡是自己的GPU一律支持CUDA,无论是Tesla,GeForce还是Quadro,虽然,Tesla和GeForce或者Quadro都不一样。
相对于768 MB的的GeForce 8800 GTX,Tesla的第一代产品就已经拥有1.5GB的显存,虽然在当时优势不是特别明显,但是如今NVIDIA突然拿出了今年秋季才正式推出的第10代Tesla C1060拥有了高达4GB的显存,和GTX 280长的很像,可惜后者只有可怜的1GB显存而已。
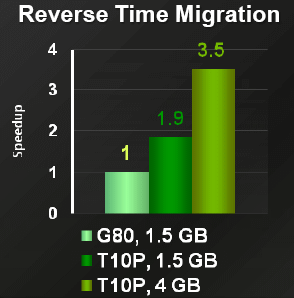
第十代Tesla拥有两款产品,一个是单卡,一个是1U,1U配备了4块上述的卡,只配备了2块卡的“Quadro Plex”这次只能捉襟见肘了。和8代不同,10代使用了特别的PCB板,有32层,只有这样才能装上4GB的显存颗粒,颗粒为DDR3 800 MHz,提供了95.4 GB/s的带宽。



和GTX 280不同,Tesla 10只需要一个6pin的PEG接口,这是因为Tesla 10是运算专用,一些专门用来渲染,处理3D图像的晶体管在Tesla里被关闭,导致功耗大幅度下降。
通过CUDA使用GPU运算涵盖许多领域,包括从模拟烹饪比萨饼在微波和传统的焦炉中热量之类的,有医学,财务,化学,生物等等。
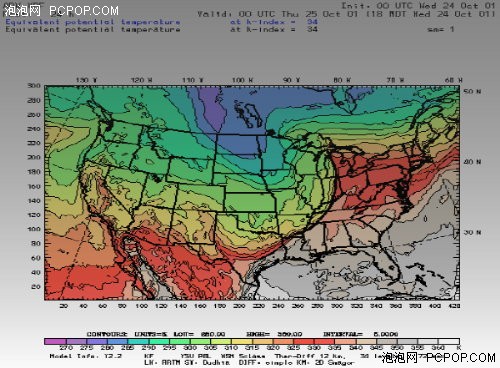
就拿模拟天气来说,GPU的效率是CPU的20倍以上。
光学矫正:这利用了NVIDIA显卡的一个光学仿真技术,借鉴面具结构。这是一个相当复杂的过程,以前需要数以千计的CPU群数天的计算。而现在,似乎简单多了。
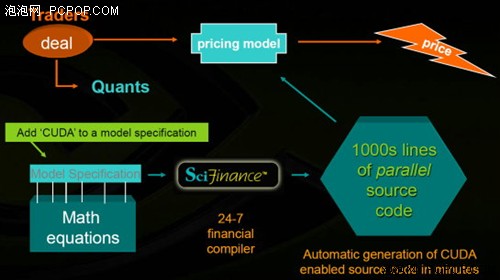
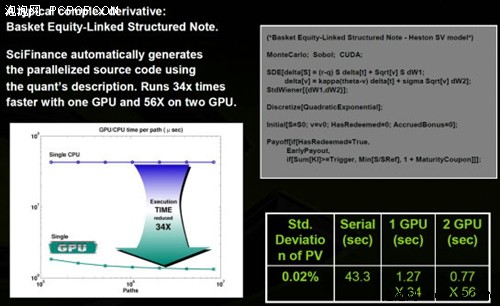
模拟市场:使用CUDA的GPU ,允许更迅速和更优质的接触金融市场,精确到即便是一次火车时间都不会有任何延误。

这是一个TechniScan的乳腺癌检测仪,它能提供许多精准的超声数据,通过GPU构建三维图像,医生结合图像诊断病情。
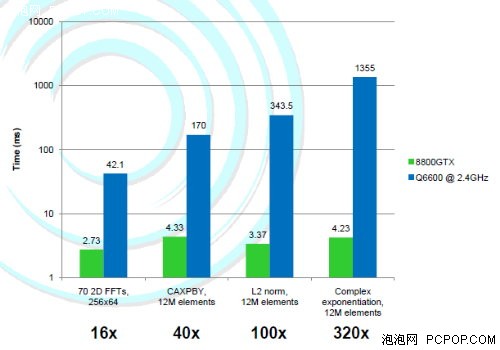
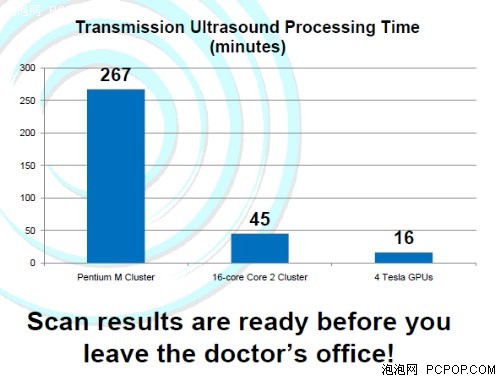
作为计算机部分的成本,需要10,000美元购买Tesla,而产生的效益则是20,000元。CUDA的出现帮助设计了一个更好的产品,增加了竞争力。

暴力破解MD5:我们使用的软件是elcomsoft ,而elcomsoft使用分布式密码恢复,是找回密码的一个好工具。
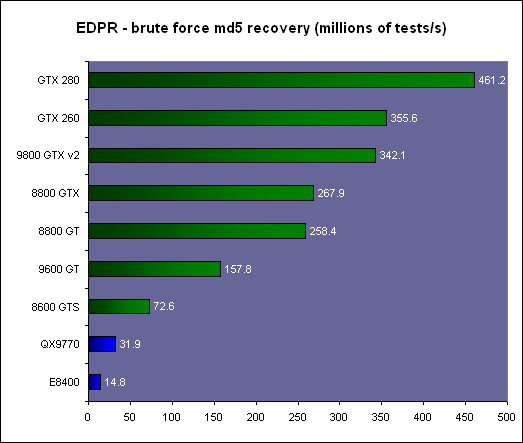
14倍速度于Intel目前最高端的CPU Core 2 Extreme QX9770,GeForce 280 GTX证明了CUDA有多强大。
实际上,AMD作为开发以GPU为计算单位的图形芯片很久了,而现在AMD高层坦诚在GPGPU方面已经和NVIDIA有了不小的差距。AMD作为先驱,并非是输给了硬件,而是在软件部分面对CUDA不知所措。
作为第一家表示对GPU计算产生兴趣,第一家提供专业显卡,第一家开发双精度64位浮点运算的AMD,却一直未能放出自己的开发包,虽然目前情况有所改善,但和之前的目标相比真是......
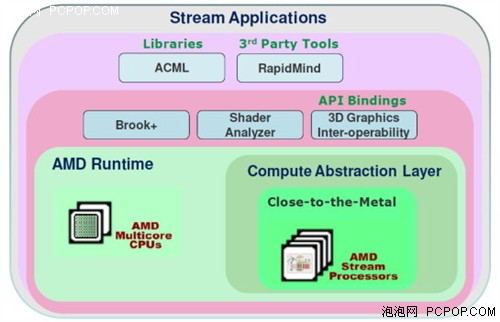
从第一个工具包SDK到现在一次又一次的版本更新,NVIDIA确实在为开发GPU的运算能力而努力,CUDA的强大逐渐被人们所认知,也许,在未来真有取代CPU成为主流的一天。

展望未来,科技的发展必然带来更加激烈的竞争,业界三巨头Intel、NVIDIA、AMD,无时不刻的在加强自己的力量,三个公司犹如五行相生相克一样环环相扣,至于谁更强大或者将一统天下谁也说不清楚,至少,在GPU运算领域,NVIDIA是走在了时代的尖端上,但Intel雄厚的实力也不容忽视,而且Intel也及时的意识到了CPU发展遭遇瓶颈,而GPU则是大有可为,未来无论GPU硬件还是GPGPU计算,前途都是一片光明!<
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}