

DX10显卡中端对决!HD2600大战GF8600
ATI从R520到R580核心,将像素渲染单元翻了三倍之多,但纹理单元的数量和性能没有改进,因为ATI认为今后的游戏中纹理操作指令并没有增多,而且所占比重逐年下降。到了DX10时代,ATI的流处理器阵容非常恐怖,那么纹理单元有何变化呢?
第三章\\第三节 RV630 VS. G84 之 纹理单元
首先来看看RV630的对手——G84在纹理单元部分有些类似于传统的管线式架构,只不过传统GPU是每个ALU绑定TMU,而G84是每组流处理器(16个)阵列绑定一组TMU&L1&L2,这种架构非常灵活,也很容易衍生出一系列产品。
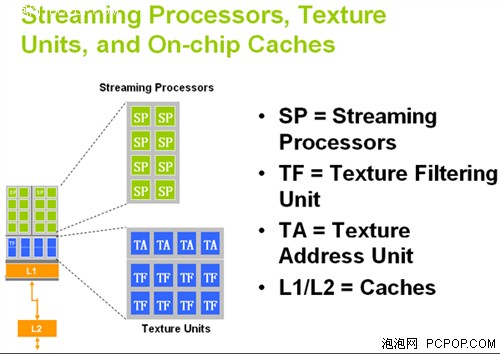
 G84的2组Shader阵列绑定了纹理单元和L1/L2缓存
G84的2组Shader阵列绑定了纹理单元和L1/L2缓存与G84每组流处理器阵列绑定纹理单元&缓存不同,RV630的纹理单元与流处理器部分是分开的,都受到Thread Processor的统一调度,这种架构沿用R520/R580的设计,但在结构部分改动特别大。
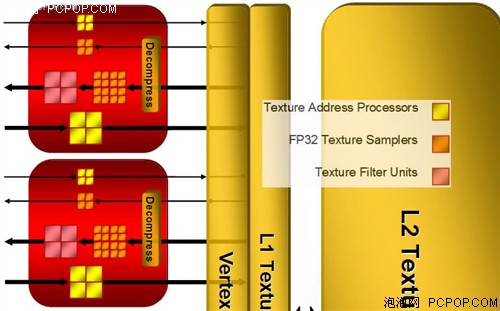 RV630的纹理单元及缓存部分
RV630的纹理单元及缓存部分
RV630包含2组纹理单元(R600的一半),但在每个纹理单元内部包含了8个纹理寻址单元(黄色,共16个),20个32位浮点纹理采样单元(橘黄色,共40个),和4个纹理过滤单元(深红色,共8个)。
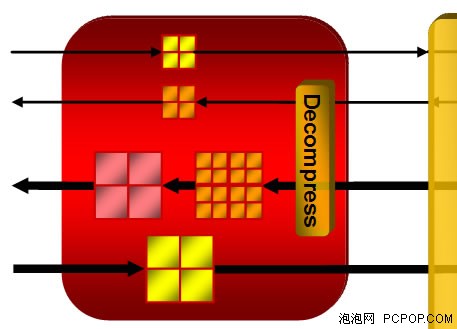 RV630单个纹理单元的内部结构
RV630单个纹理单元的内部结构再来看看细节部分,可以看到8个黄色的纹理寻址单元和20个FP32纹理采样单元还要区分大小,这是因为顶点着色只能使用到其中4个小纹理寻址单元进行纹理采样,而像素/几何着色则可以使用全部的8个;顶点着色只能使用其中4个小FP32纹理采样单元,而像素/几何着色则可以使用全部的20个。
可能很多人都比较奇怪RV630怎么会有这么多的FP32纹理采样单元,这是因为Shader Mode 4.0只能支持128Bit色彩精度(IEEE FP32)纹理采样,而且Textures和Samplers现在是各自独立的,程序会大量使用Sampler指令,因此独立、大规模的FP32纹理采样单元可以大幅提升纹理贴图效率和高分辨率纹理精度。
现在就可以知道,RV630和G84的纹理单元数量是相等的,如此一来,X1000系列在纹理方面大幅落后于GF7系列的情况,将不会在HD 2600身上重演,HD 2600可望在老游戏和OpenGL游戏中反超GF8!
第三章\\第四节 RV630 VS. G84——光栅单元规格解析
ATI的Render Back End(后期渲染)其实就相当于NVIDIA的ROP(Raster OperATIon Processor光栅操作处理器),其主要作用就是像素输出,但是它还担负了Z(深度)操作、抗锯齿取样等繁重任务,在DX10中被称作“Output Merger”。
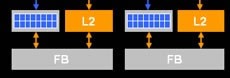 G84拥有2组ROP单元
G84拥有2组ROP单元
G8X的架构都是分块式的,每一个ROP单元包含64bit显存控制器,G84拥有两个ROP单元,每个ROP可以处理4个像素,因此就是8个ROPs。
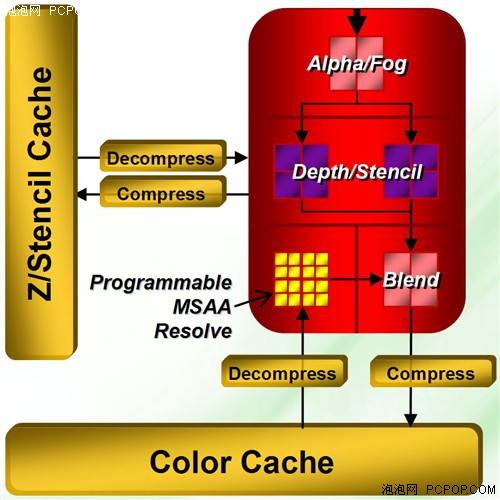 RV630只有1个后期输出模块
RV630只有1个后期输出模块
与G84相同,RV630也提供了最大8个MRT(Multiple Render Target),直接支持8xMSAA。其最大的特点就是可编程AA模式,可以在2/4/8xMSAA的基础上衍生出N多种高效率的CFAA(最大24x)。
但是RV630最大的缺点就是只有1个后期输出模块(R600有4个),这可能会导致它的AA效能偏低。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}