

DirectX支配游戏!历代GPU架构全解析
★ 首款DX9显卡——Radeon 9700
当NVIDIA沉浸于GeForce 4 Ti大获全胜的DX8时代时,ATI在DX9标准正式确立之前就提前发布了Radeon 9700显卡,打得NVIDIA措手不及。这款产品来得如此突然,以至于ATI发布之时甚至没有提供相关技术PPT/PDF。

由于DX9相比DX8并没有改变3D渲染流程,仅仅是强化了ShaderModel指令集,因此R300的架构相比R200改进并不大,主要的变化是规模的扩充与外围控制模块的加强。比如:首次使用256bit显存控制器、类似CPU的FCBGA封装、更先进的纹理压缩技术以及后期处理单元。
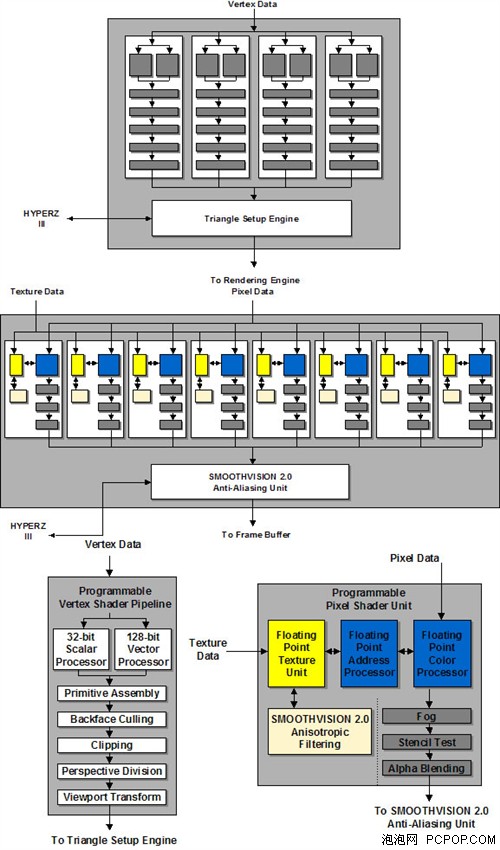
R300的顶点和像素着色单元结构
当然,R300的Shader单元经过了重新设计,定址、色彩和纹理单元都支持浮点运算精度,这是它能够完美运行DX9程序的关键。R300核心拥有8条像素渲染管线及4个顶点着色单元,每条像素管线中只有1个纹理单元。至此ATI的像素与纹理的比例从1:3到1:2再到1:1,在DX9C时代将会进一步拉大至3:1,也就是风靡一时的3:1架构,当然这是后话了。
★ NVIDIA遭遇滑铁卢——GeForce FX 5800
NV30核心采用了业界非常先进的0.13微米工艺制造,并使用了最高频率的GDDR2显存,而且发布时间较晚,理应占尽优势才对。但是这一次NVIDIA没能跟上微软的步伐,不仅在时间上晚于ATI,而且在DX9技术方面也未能超越。NV30的架构存在较大的缺陷,NVIDIA艰难的完成了从DX8到DX9的过渡,但结果很不理想。
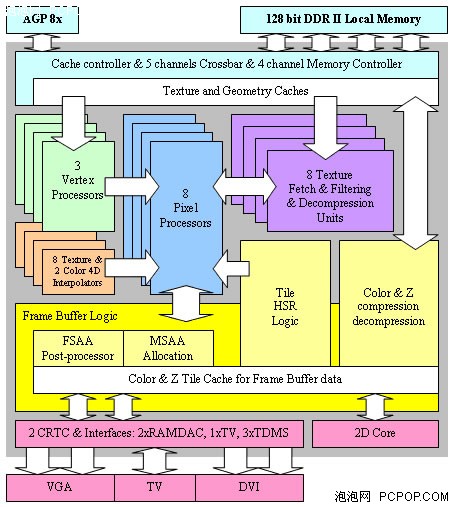
从宏观上说,NV30的整体架构更像是一个DX7(固定功能TRUE T&L单元)、DX8(FX12combiner整数处理单元)、DX9(浮点像素单元)的混合体。而在DX9的应用中,不能出现非浮点精度的运算,所以前两者是不起作用的,造成了NV30晶体管资源的浪费,同时也影响了性能。
NV30的PiexlShader单元没有Co-issue(标量指令+矢量指令并行处理)能力,而在DX9中,单周期3D+1D是最常见指令处理方式,即在很多情况下RGB+A是需要非绑定执行的,这时候NV30就无法并行执行,指令吞吐量大大降低。其次,NV30没有miniALU单元,也限制了NV30的浮点运算能力(在NV35中DX8整数单元被替换为miniALU)。
另外,NV30在寄存器设计(数量及调用方式)、指令存储方式(读写至显存)等方面也有缺陷。NV30的寄存器数量较少,不能满足实际程序的需要。而且,用微软的HLSL语言所编写的pixel shader2.0代码可以说NV30的“天敌”,这些shader代码会使用大量的临时寄存器,并且将材质指令打包成块,但是NV30所采用的显存是DDR-SDRAM,不具备块操作能力。同时,NV30材质数据的读取效率低下,导致核心的Cache命中率有所下降,对显存带宽的消耗进一步加大。
由于NV30是VILW(超长指令,可同时包含标量和SIMD指令)设计类型的处理器,对显卡驱动的Shader编译器效率有较高的要求。排列顺序恰当的shader代码可以大幅度提升核心的处理能力。在早期的一些游戏中,这种优化还是起到了一定的作用。但对于后期Shader运算任务更为繁重的游戏则效果不大。
最终,虽然NV30与上代的NV25相比架构变化很大,但性能方面全面落后与对手的R300。不过NV30的架构还是有一定的前瞻性,ATI的R600在Shader设计方面与NV30有很多相似之处。
★ 小结:非“真DX9架构”导致NV30失败
现在再来看看,相信没人会认为DX9的改进有限了。正是由于NVIDIA没能适应DX9所带来ShaderModel指令的诸多改进,采用DX8+DX9混合式的架构,才导致NV30存在很大缺陷,在运行DX9游戏时效率很低。另外冒险采用先进工艺、不成熟的GDDR2显存、128bit位宽这些都极大的限制了NV30的性能,即便在DX8游戏中都无法胜过R300。
而ATI则占据天时地利人和等一切优势,完全按照DX9标准而设计,甚至在DX9标准确立之前就早早的发布了DX9显卡,这不免让人感觉ATI和微软之间存在微妙的关系,“阴”了NVIDIA一把。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}