

Maxwell领衔!A/N新显卡能效深度测试
在这里我们不难看出,Maxwell内部所有单元和横梁结构均得到了重新设计,数据流得到了优化,功率管理实现了大幅改变。
虽然从图形特性的视角来看,第一代Maxwell GPU可提供与Kepler GPU相同的API功能,但从深层来上,Maxwell还在单个GPC(图形处理簇)内实现了多个SM单元,每个SM包含一个多形体引擎(Polymorph Engine)和纹理单元,而每个GPC包含一个光栅引擎(Raster Engine)。ROP依然与二级高速缓存片(L2 Cache Slice)以及显存控制器联系在一起。
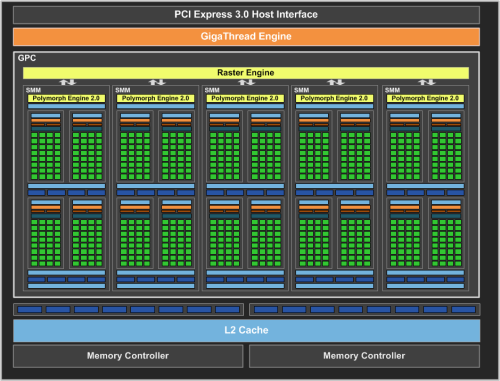
GM107全芯片框图
GM 107 GPU包含一个GPC、五个Maxwell流式多处理器(SMM)以及两个64位显存控制器(共128位)。这就是这一芯片的完整实现形式,与GeForce GTX 750Ti中的芯片配置相同。
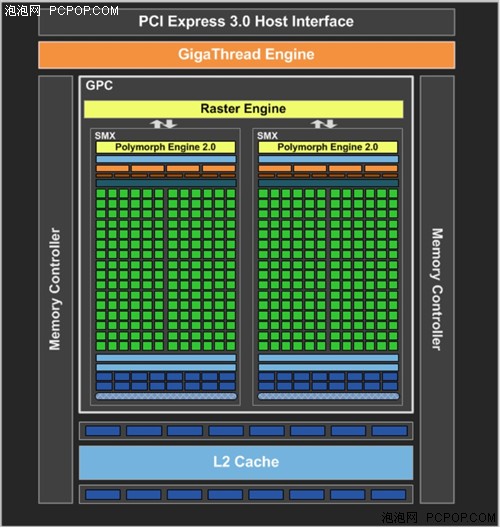
GK107全芯片框图
SMX 处理核架构
上一代Kepler的方法是划分为非2幂(non-power-of-two)数量的CUDA核心,其中一些是共享核心,这种方法需要的SM调度器数量较少,但复杂程度较高,在各种各样的游戏引擎环境中表现并不理想。
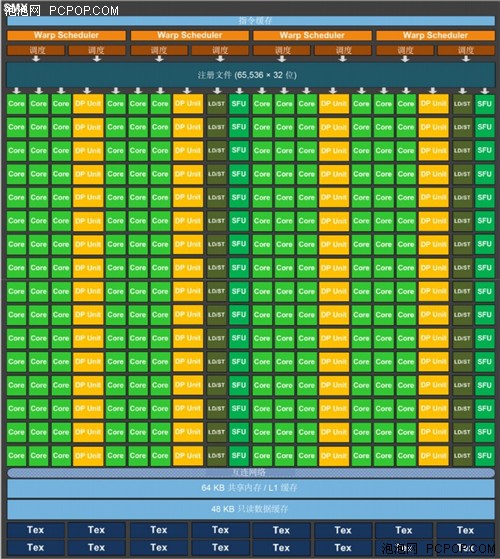
SMX: 192个单精度CUDA核、64个双精度单元、32个特殊功能单元(SFU)和32 个加载/存储单元(LD/ST)。
每个SMX单元具有192单精度CUDA核,每个核完全由浮点和整数算术逻辑单元组成。Kepler完全保留Fermi引入的IEEE 754-2008 标准的单精度和双精度算术,包括积和熔加(FMA)运算。
成对的处理块共享四个纹理过滤单元和一个纹理高速缓存。计算一级高速缓存的功能现在也与纹理高速缓存功能相结合,而共享显存是一个独立的单元(类似首款CUDAGPU——G80中所使用的方法),被全部四个块共享。
SMM 处理核架构
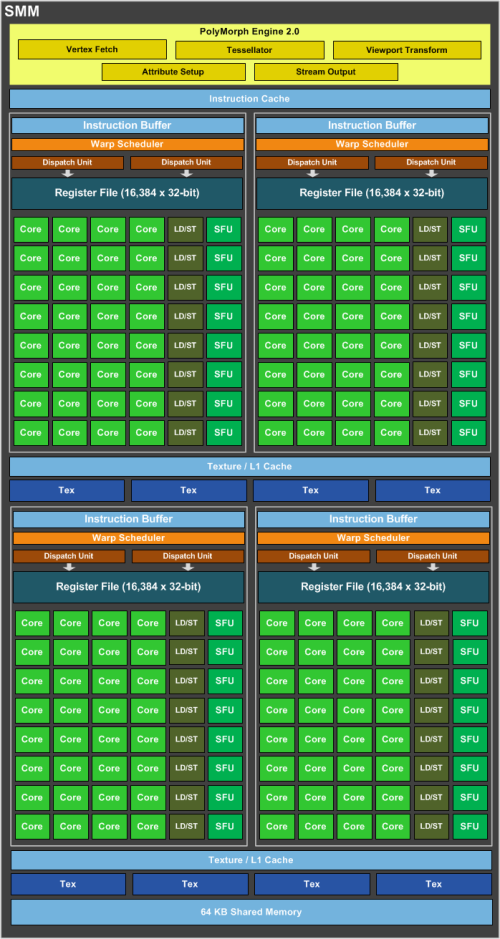
Maxwell SM框图
而现在每个SM分为四个独立的处理块,每个处理块具备自己的指令缓冲区、调度器以及32个CUDA核心。新的划分方法简化了设计与调度逻辑、节省了晶体管与功耗、降低了计算延迟。
总体而言,在这一全新设计上,每个“SM”的尺寸得到大幅缩减,而性能却能够达到一个KeplerSM的90%。更小的晶体管消耗让NVIDIA能够在每颗GPU中实现更多数量的SM。通过对比GK107和GM107 SM总数的相关指标可发现,GM107有五个SM,而前者只有两个。GM107的峰值纹理性能比前者高25%,CUDA核心数量多1.7倍,着色器性能大约高2.3倍。
● SMM架构显存系统的改进
对GM107来说,要在显存位宽与GK107相同的情况下实现性能大幅提升的目标,增强显存系统也同样重要。内部显存系统带宽实现了提升,另外这一设计的效率也得到了改善。此外,2MB大容量二级高速缓存配置(比之前的任何GPU设计都大)十分有效地降低了显存带宽需求,确保了DRAM带宽不成为瓶颈。
其他关于Maxwell架构的基本信息,例如通过Giga Thread引擎的主PCI Express接口数据流、Polymorph与Raster单元的基本操作等等过于晦涩的知识这里就不再赘述了。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}