

挑战卡皇TITAN!GTX 780 SLI巅峰测试
Kepler GK110的新SMX引入几个架构创新,使其不仅成为有史以来最强大的多处理器,而且更具编程性,更节能。
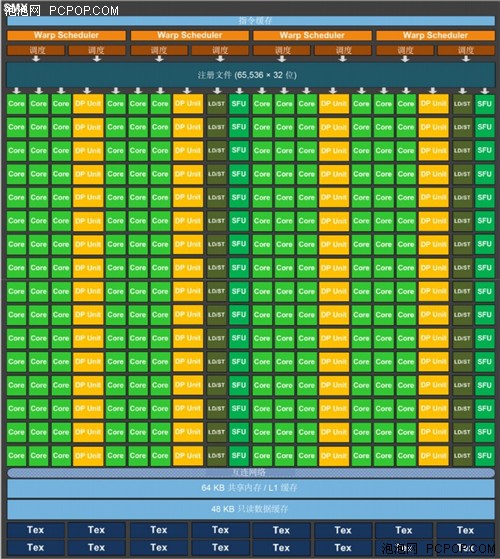
SMX: 192个单精度CUDA核、64个双精度单元、32个特殊功能单元(SFU)和32 个加载/存储单元(LD/ST)。
SMX 处理核架构
每个Kepler GK110 SMX单元具有192单精度CUDA核,每个核完全由浮点和整数算术逻辑单元组成。Kepler完全保留Fermi引入的IEEE 754-2008 标准的单精度和双精度算术,包括积和熔加(FMA)运算。
Kepler GK110 SMX 的设计目标之一是大大提高GPU的双精度性能,因为双精度算术是许多HPC应用的核心。Kepler GK110 的SMX还保留了特殊功能单元 (SFU)以达到和上一代GPU类似的快速超越运算,所提供的SFU数量是Fermi GF110 SM的8倍。
与GK104 SMX单元类似,GK110 SMX单元内的核使用主GPU频率而不是2倍的着色频率。2x着色频率在 G80 Tesla 架构的 GPU 中引入,并用于之后所有的 Tesla 和 Fermi‐架构的GPU。在更高时钟频率上运行执行单元使芯片使用较少量的执行单元达到特定目标的吞吐量,这实质上是一个面积优化,但速度更快的内核的时钟逻辑更耗电。对于Kepler,我们的首要任务是的性能/功率比。虽然我们做了很多面积和功耗方面的优化,但是我们更倾向优化功耗,甚至以增
加面积成本为代价使大量处理核在能耗少、低GPU频率情况下运行。
Quad Warp Scheduler
SMX以32个并行线程为一组的形式调度进程,这32个并行线程叫做Warp。而每个SMX中拥有四组 Warp Scheduler 和八组 Instruction Dispatch 单元,允许四个Warp同时发出执行。Kepler 的 Quad Warp Scheduler 选择四个 Warp,在每个循环中可以指派每 Warp 2 个独立的指令。与 Fermi 不同,Fermi 不允许双精度指令和部分其他指令配对,而 Kepler GK110 允许双精度指令和其他特定没有注册文件读取的指令配对 例如加载/存储指令、纹理指令以及一些整数型指令。
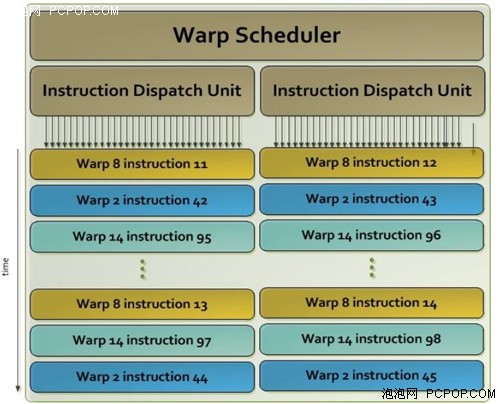
每个Kepler SMX 包含4组Warp Scheduler,每组Warp Scheduler包含两组 Instruction Dispatch单元。单个Warp Scheduler单元如上所示。
我们努力优化SMX Warp Scheduler逻辑中的能源。例如,Kepler和Fermi Scheduler 包含类似的硬件单元来处理调度功能。其中包括:
a) 记录长延迟操作(纹理和加载的寄存器
b) Warp 内调度决定(例如在合格的候选 Warp 中挑选出非常好的 Warp 运行)
c) 线程块级调度(例如,GigaThread 引擎)
然而,Fermi的scheduler还包含复杂的硬件以防止数据在其本身数学数据路径中的弊端。多端口寄存器记录板会纪录任何没有有效数据的寄存器,依赖检查块针对记录板分析多个完全解码的 Warp指令中寄存器的使用情况过,确定哪个有资格发出。
对于 Kepler ,我们认识到这一信息是确定性的(数学管道延迟是不变量),因此,编译器可以提前确定指令何时准备发出,并在指令中提供此信息。这样一来,我们就可以用硬件块替换几个复杂、耗电的块,其中硬件块提取出之前确定的延迟信息并将其用于在 Warp 间调度阶段屏蔽Warp,使其失去资格。
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}