

完美DX10!ATI新王者HD2900XT权威评测
● 第三章 第五节 几何Shader以及 Stream Out
直到现在,图形硬件只有在GPU上操作已有数据的能力。顶点着色器(Vertex Shader)和像素着色器(Pixel Shader)都允许程序操作内存中已有的数据。这种开发模型非常成功,因为它在复杂网格蒙皮和对已有像素进行精确计算方面都表现的很出色。但是,这种开发模型不允许在图像处理器上生成新数据。当一些物体在游戏中被动态的创建时(比如新型武器的外形),就需要调用CPU了。可惜现在大多数游戏已经很吃CPU了,游戏进行时动态创建庞大数量新数据的机会就变得微乎其微了。
Shader Model 4.0中引入的几何着色器(Geometry Shader),第一次允许程序在图像处理器中创建新数据。这一革命性的事件使得GPU在系统中的角色由只可处理已有数据的处理器变成了可以以极快速度既可处理又可生成数据的处理器。在以前图形系统上无法实现的复杂算法现如今变成了现实。使用DirectX 10和Geforce 8800 GTX,类似模板阴影(Stencil Shadow)、动态立方体贴图(Dynamic Cube Map)、虚拟位移贴图(Displacement Mapping)等依靠CPU或多通道渲染(Multi-Pass Rendering)的算法效率提升了很多。
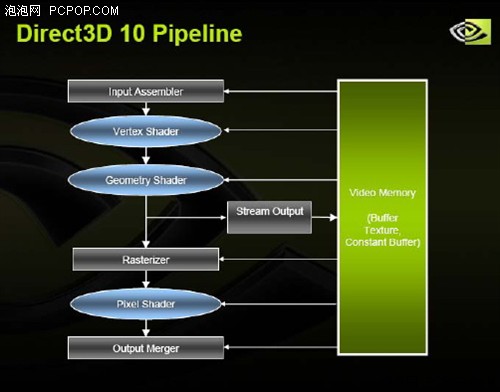
 DirectX 10流水线加入了几何着色器和数据流输出(Stream Output),使GPU可以在不用CPU干涉的条件下进行反复运算。
DirectX 10流水线加入了几何着色器和数据流输出(Stream Output),使GPU可以在不用CPU干涉的条件下进行反复运算。
几何着色器被放在顶点着色器和光栅化阶段(Rasterizer)中间。所谓光栅化,就是一行一行的扫描每个三角形,把它们一个像素一个像素的绘制到画面上。几何着色器把经过顶点着色器处理过的顶点当作输入,对于每个顶点,几何着色器可以生成1024个顶点作为输出。这种生成大量数据的能力叫做数据扩大(Data Amplification)。同样的,几何着色器也可以通过输出更少的顶点来删除顶点,因此,就叫做数据缩小(Data Minimization)。这两个新特性使GPU在改变数据流方面变得异常强大。
1 细分的虚拟位移贴图(Displacement Mapping with Tessellation)
几何着色器终于让虚拟位移贴图可以在GPU上生成了。虚拟位移贴图是在离线渲染系统中非常流行的一项技术,它可以用一个简单的模型和高度图(Height Map)渲染出非常复杂的模型。高度图是一张用来表示模型上各点高度的灰度图。渲染时,低多边形的模型会被细分成多边形更多的模型,再根据高度图上的信息,把多边形挤出,来表现细节更丰富的模型。
因为在DirectX 9中,GPU无法生成新的数据,低多边形的模型无法被细分,所以只有小部分功能的虚拟位移贴图可以实现出来。现在,使用DirectX 10和R600的强大力量,数以千计的顶点可以凭空创造出来,也就实现了实时渲染中真正的细分的虚拟位移贴图。
2 基于边缘(Adjacency)的新算法
几何着色器可以处理三种图元:顶点、线和三角形。同样的,它也可以输出这三种图元中的任何一种,虽然每个着色器只能输出一种。在处理线和三角形时,几何着色器有取得边缘信息的能力。使用线和三角形边缘上的顶点,可以实现很多强大的算法。比如,边缘信息可以用来计算卡通渲染和真实毛发渲染的模型轮廓。

使用几何着色器的非照片模拟渲染
(Non-Photorealistic Rendering - NPR)
3 数据流输出(Stream Output)
在DirectX 10之前,几何体必须在写入内存之前被光栅化并送入像素着色器(pixel shader)。DirectX 10引入了一个叫做数据流输出(Stream Output)的新特性,它允许数据从顶点着色器或几何着色器中直接被传入帧缓冲内存(Frame Buffer Memory)。这种输出可以被传回渲染流水线重新处理。当几何着色器与数据流输出结合使用时,GPU不仅可以处理新的图形算法,还可以提高一般运算和物理运算的效率。
在生成、删除数据和数据流输出这些技术的支持下,一个完整的粒子系统就可以独立地在GPU上运行了。粒子在几何着色器中生成,在数据扩大的过程中被扩大与派生。新的粒子被数据流输出到内存,再被传回到顶点着色器制作动画。过了一段时间,它们开始逐渐消失,最后在几何着色器中被销毁。

关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}