

无人机/机器人开发 如何优化深度学习?
从能够自主飞行的无人机,到能和小朋友玩物体识别等游戏的机器人,极客们对智能设备追求没有止境。除了轻巧的体积、超长的续航,更重要的是要有一个智能的“大脑”,来实现人类能够想得到的人机交互,或者智能化的自主决策和行为动作,毫无疑问强大的深度学习能力不可或缺。那么,拒绝束缚人类想象力的嵌入式智能设备,其开发工作需要什么样的环境和工具?开发者进行相关开发的可行思路是什么?近日,CSDN记者就此专访了智能设备重度开发者、高性能计算专家赵开勇(博客:http://blog.csdn.net/openhero)。
> 赵开勇,香港浸会大学计算机计算机系异构计算实验室在读博士,长期从事高性能计算领域研究,在CPU、GPU异构计算方面有多年的研究经验,尝试过多种嵌入式开发平台,曾在2013年初预言基于移动设备的高性能计算将会成为未来潮流。
CSDN:对于嵌入式领域的人工智能应用开发工作,您认为计算方面的挑战有什么不同?
赵开勇:智能应用基本都需要使用深度学习做视觉处理、语音识别,深度学习可以说是构建智能应用的大脑的必备工具。现在的深度神经网络参数一般都比较庞大,上百层的网络已经不少,并且每一层又有很多参数。如果是按照F32的数据,就需要耗费几百MB的内存。所以如何把网络数据变小,同时又不损失精度,这是在嵌入式领域做人工智能的挑战之一。
另一个方面,嵌入式的平台的计算能力也比不上传统的PC,计算能力有限,一些复杂的神经网络也需要在嵌入式平台上做相应的优化,才能在嵌入式平台上达到接近PC上的神经网络的速度。
总而言之,嵌入式平台上的计算能力和计算资源有限都是深度学习在嵌入式平台上的挑战。
CSDN:能否介绍近期您有做过哪些相关的尝试?
赵开勇:我借助NVIDIA最近推出的Jetson TX1平台开发了一些图像处理的应用(细节暂时不便公布),采用的算法主要是深度学习中最常用的卷积神经网络(CNN),它能够解决图像处理的大部分问题。CNN的关键是卷积层,卷积可以看做是对图像做滤波提取特征值,但是需要大量的计算——目前能work的众多CNN网络,卷积部分占了70%以上的计算时间,所以这部分的优化是很有必要的。
我基于Jetson TX1针对卷积计算做了一些性能上的优化,包括让CPU、GPU、内存在最高频率中运行,以及内存优化,就是CPU、GPU内存协同调度。
GPU优化的考虑,我认为是算法>并行化>硬件特性。除了降低算法复杂度的考虑,并行计算就是空间换时间,重要的两个方面是更多利用高效的缓存空间,和针对硬件并发特性更高效地利用网络并发。所有的卷积核可以一起对一张图片进行卷积运算,分别存储到不同的位置,这样不需要多次访问图片,但会增加内存的使用量。同时,我们可以把卷积核心和图像展开,卷积问题转换成矩阵乘法。相比于矩阵乘法,采用快速傅里叶变换(FFT)可能更快,但FFT会存在精度不足的问题,比如机器人的视觉识别、无人机的避障可能会受到影响。
在GPU上的优化乘法,需要对硬件架构有比较深入的了解。但是再深入考虑,可以抓住以下几个点:
1. 了解IO访问的情况和IO的性能;
2. 多线程的并行计算特性;
3. IO和并行计算间的计算时间重叠。
NVIDIA的GPU内存访问的一个特性,连续合并访问,可以很好地利用硬件的带宽。从架构来看,优化IO访问,即使核心数目没增加多少,架构也没太大变化,只是在几个计算流处理器中间增加缓存,就能提高很大的性能。所以说,矩阵乘法的优化,要充分利用GPU里面的缓存机制,也就是shared memory和register,尽量把多个数据都放到里面,多次读写的速度就会快很多。
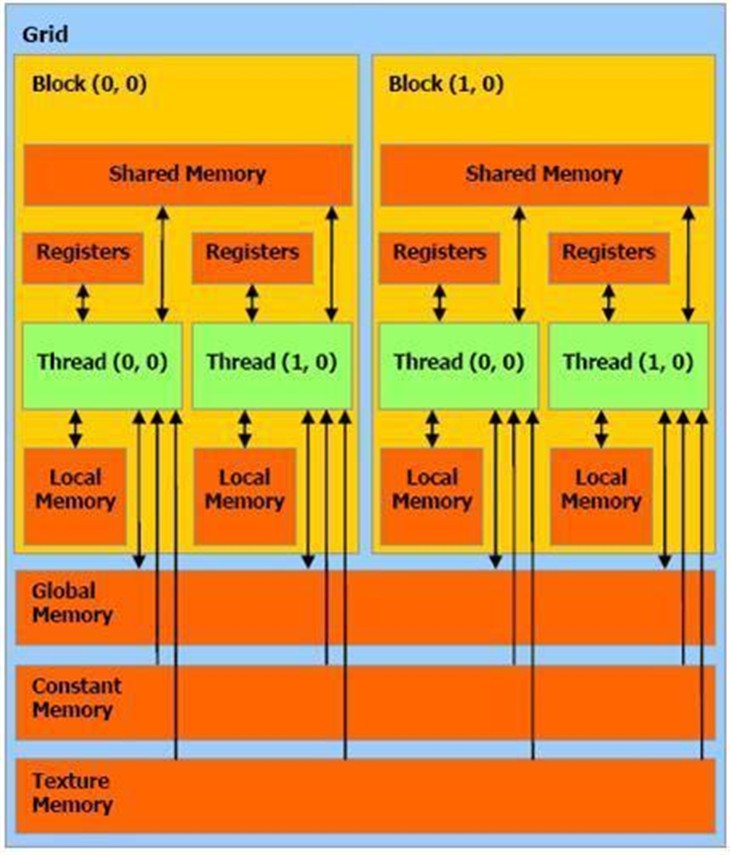
经典的GPU内存架构与线程模型
另外一个技巧,在考虑对A矩阵和B矩阵的访问时,可以把B矩阵的数据大量放到shared memory里面,提高shared memory的公用性。
> Jetson TX1是NVIDIA针对无人机、机器人、智能车载等智能设备领域推出的GPU模块,基于Tegra X1处理器打造,包括一个基于Maxwell架构、256个CUDA核心、浮点运算能力达到Teraflop级的GPU,64位ARM A57芯片组、4GB LPDDR4 RAM 内存(每秒带宽速度达25.6Gbps)、16GB本地存储模块、802.11 2×2 ac Wi-Fi解决方案以及1Gbps以太网端口,同时还配备面向视觉计算的Jetson TX1开发者套件。

(Jetson TX1,图片来自NVIDIA官网)
CSDN:Jetson TX1能解决您刚才谈到的两个挑战吗?有哪些环节,在采用Jetson TX1之前实现起来比较困难?
赵开勇:其实嵌入式人工智能应用需要的不仅仅是计算。选择TX1主要有四个理由:
1. 计算模块从I/O扩展开发平台独立,TX1的核心板只有卡片大小(50 mm x 87 mm),所以可以很方便做前期的验证平台,甚至直接上产品而不需要再做设计。
2. 性能方面接近1024G flops的F16计算能力,只有10w左右的功耗,完全支持CUDA和cuDNN的接口,可以很方面地把PC上训练的深度神经网络直接porting到Tegra X1的嵌入式平台上。
3. TX1提供丰富的硬件接口,可以很方面接入各种硬件设备,包括摄像头、各种传感器等。
4. TX1开发者套件利用Linux环境进行了预先闪存处理,支持许多常见的API,受NVIDIA完整开发工具链的支持。此外,NVIDIA的工具对Caffe等主流的深度学习开源软件支持得很好。

(图片来自NVIDIA官网)
谈到使用TX1才能做到的,尺寸和功耗的优化无疑是令人激动的,但我最看重还是视觉计算性能——卷积计算的优化对于我们的应用迭代实在太重要了。虽然目前的深度学习硬件类型比较多,但是真正能快速形成战斗力的,还是CUDA硬件+CUDA深度学习软件。GPU架构本身就是一种可编程的并行计算架构,并行计算在70年代就有很多很好的算法。但NVIDIA在核心数量、浮点运算能力、内存等方面的进展,使得GPU性能能够不断增长,256核心让TX1的并行计算能力更好。
另外很重要的一点,Tegra采用与台式机一样的架构,所以个人开发者也可以在台式机上用更强的游戏卡(推荐Titan系列)来训练深度神经网络,然后很方便地移植到嵌入式平台上,有利于复杂多维空间图像信息的快速处理。
CSDN:您谈到性能,也曾预言基于移动设备的高性能计算将会成为未来潮流,现在Jetson TX1提供Teraflop级的浮点运算能力,在实际测试中的表现符合您的预期吗?
赵开勇:预言不用交税,但技术突破需要很多工作。TX1的计算能力确实达到了Teraflop级别,在一张信用卡大小的系统上实现,为嵌入式智能设备开发者提供了一个很好的平台,同时我们也看到,目前只是F16的,而很多深度学习或者神经网络是F32的,所以还有一定的局限性,当然技术会不断地发展。另一方面TX1的真正的应用还是比较少,虽然NVIDIA在TX1上提供了大量的软件包,但是在实际生成中大规模的使用TX1的还是太少,还需要更多的人员参与到TX1的应用开发中来,TX1的性能才能真正发挥出来。
其实NVIDIA在TX1的软件方面已经提供了大量的支持,因为TX1上使用的是PC级别的GPU架构,可以很方便地把PC上的一些应用直接porting到TX1上来。不过,真正了解如何把深度神经网络优化到TX1上,还需要更多的人参与。
对于TX1的性能本身,我认为,嵌入式高性能计算平台在不久的将来还会有更高的性能,TX1只是一个起步。
CSDN:能否谈谈CPU、GPU内存协同调度的经验?
赵开勇:TX1的CPU和GPU其实是共享一片硬件内存,所以在使用的时候,需要注意内存的管理,需要采用高效的内存管理方法来做开发。当然内存调度管理是所有开发平台都需要注意的事情,只是在TX1可能会体现得更明显——如果内存调度管理不好,在GPU上实现的高性能应用可能会受到内存制约,使得性能下降很多,在嵌入式平台上性能就会损失更多。
前面提到过,想要实现更好的优化,需要了解GPU内部的硬件架构,包括内存架构和线程模型。这方面的入门知识,可以参考我的CSDN博客文章:http://blog.csdn.net/openhero/article/details/42131771
CSDN:您是否还尝试过其他类型的嵌入式开发平台?和Jetson TX1的开发体验相比有什么区别?
赵开勇:尝试过一些。有的提供更简单的开发平台,但是没有TX1的性能高,很难做出一些真正酷的应用;有的开发难度更大,提供的软件资源不多。
CSDN:最近有一些无人驾驶汽车撞人、无人机坠毁的新闻,基于Jetson TX1的开发也有一些安全方面的优势吗?
赵开勇:这其实和硬件关系不大,重要的是开发过程中需要对安全有更高层次的考虑,需要考虑如何结合更多的传感器,尽量把各种可能性都编写到程序中,以避免安全事故的发生。
当然,增加传感器也需要计算的支持,只有丰富的计算性能和计算资源才能提供各种传感器融合所需的性能。从这个角度来看,TX1有解决安全问题的优势,因为这个平台上有丰富的计算资源,而且在未来的版本中可能会有更高的计算能力。
CSDN:您认为TX1只是一个起步,那么对于它的升级版本的能力,包括编程的支持,您还有哪些期待?
赵开勇:主要是如下几个方面:
1. 更高的性能,更多的功耗,更小的硬件平台,不需要太多的外围设备,把核心板做得更小。
2. 编程方面支持更多的直接从PC移植,更好的工具将PC上开发深度网络,直接优化到TX1的平台上。
3. 提供更多稳定丰富的SDK,在PC上提供相同的开发软件包,这样就可以在PC上很快速地开发,然后移植到TX1上。
小结
在VR、机器人、无人机、自动驾驶泛滥的时代,将人工智能技术应用到嵌入式和移动领域的技术趋势已经不可阻挡,但这些应用的开发,需要计算资源和开发接口、开发工具的支持。从赵开勇的尝试来看,Jetson TX1平台具有强大的计算能力,同时提供了丰富的开发资源,以及PC移植的能力,能够让开发者更容易地开发出想得到的应用。■
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}