

开创视觉计算帝国GTX280/260权威评测
第二章/第三节 G80革命性的标量流处理器架构解析
统一渲染架构让以往的像素管线和顶点管线成为历史,取而代之的是全新的流处理器,从而让着色单元不再区分渲染对象,提高了晶体管利用率和执行效率。目前NVIDIA和AMD的GPU都采用了统一渲染架构,但在双方的渲染单元的微架构设计却截然不同,下面就做对比分析。
● 传统SIMD(单指令多数据)架构GPU的弊端
在图形处理中,最常见的像素都是由RGB(红黄蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的运算器(ALU)。
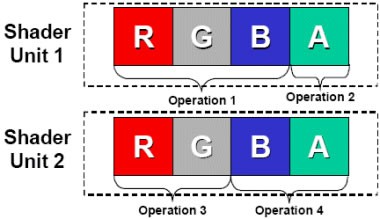
数据的基本单元是Scalar(标量),就是指一个单独的值,GPU的ALU进行一次这种变量操作,被称做1D标量。由于传统GPU的ALU在一个时钟周期可以同时执行4次这样的并行运算,所以ALU的操作被称做4D Vector(矢量)操作。一个矢量就是N个标量,一般来说绝大多数图形指令中N=4。所以,GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是SIMD(Single Instruction Multiple Data,单指令多数据流)架构。
显然,SIMD架构能够有效提升GPU的矢量处理性能,由于VS和PS的绝大部分运算都是4D Vector,它只需要一个指令端口就能在单周期内完成4倍运算量,效率达到100%。但是4D SIMD架构一旦遇到1D标量指令时,效率就会下降到原来的1/4,3/4的模块被完全浪费。为了缓解这个问题,ATI和NVIDIA在进入DX9时代后相继采用混合型设计,比如R300就采用了3D+1D的架构,允许Co-issue操作(矢量指令和标量指令可以并行执行),NV40以后的GPU支持2D+2D和3D+1D两种模式,虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上分支预测的情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。
● G80革命性的MIMD(多指令多数据)架构解析
而G80打破了这种传统设计,NVIDIA的科学家对图形指令结构进行了深入研究,它们发现标量数据流所占比例正在逐年提升,如果渲染单元还是坚持SIMD设计会让效率下降。为此NVIDIA在G80中做出大胆变革:流处理器不再针对矢量设计,而是统统改成了标量ALU单元。
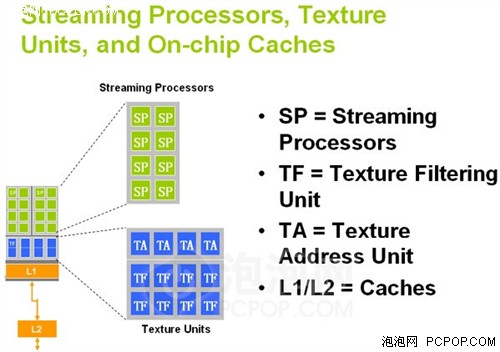
G80有8组阵列,每组阵列包含16个流处理器和8个纹理单元
如此一来,对于依然占据主流的4D矢量操作来说,G80需要让1个流处理器在4个周期内才能完成,或者是调动4个流处理器在1个周期内完成,那么G80的执行效率岂不是很低?没错,所以NVIDIA大幅提升了流处理器工作频率(核心频率的两倍以上),扩充了流处理器的规模(128个),这样G80的128个标量流处理器的运算能力就基本相当于传统的64个(128×2?)4D矢量ALU。
当然这只是在处理4D指令时的情形,随着图形画面越来越复杂,1D、2D、3D指令所占比例正在逐年增多,而G80在遇到这种指令时可说是如鱼得水,与4D一样不会有任何效能损失,指令转换效率高并且对指令的适应性非常好,这样G80就将GPU Shader执行效率提升到了新的境界!
与传统的SIMD架构不同,G80这种超标量流处理器被称为MIMD(Multiple Instruction Multiple Data,多指令多数据流)架构。G80的架构听起来很完美,但也存在不可忽视的缺点:根据前面的分析可以得知,4个1D标量ALU和1个4D矢量ALU的理论运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构!
G80的128个1D标量ALU听起来规模很庞大,而且将4D矢量指令转换为4个1D标量指令时的效率也能达到100%,但实际上如果用相同的晶体管规模,可以设计出更加庞大的ALU运算器,这就是R600统一渲染单元的架构。
● R600超标量SIMD架构的优缺点
R600核心还是采用了传统的SIMD架构,核心拥有64个Shader Units(又称Stream Processing Units),但它又在传统Shader基础上进行了该进,每个Shader内部包含了5个超标量ALU,因此AMD声称R600核心拥有64×5=320个流处理器。
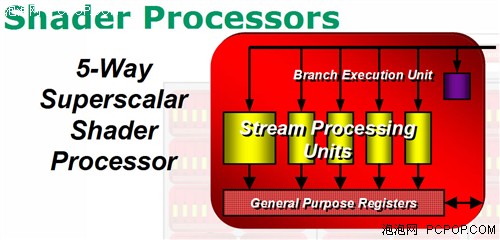
R6XX采用了5D着色单元架构
R600和G80的晶体管数是差不多的,通过前面的分析我们可以知道,G80的128个标量流处理器的理论运算能力就基本相当于传统的64个(128×2?)4D矢量ALU,而R600本身就拥有64个5D矢量ALU,再加上工艺和显存带宽优势,理论上R600应该比G80强很多才对,但实际情况恰好相反!
经过实际测试证明,拥有320个流处理器(即64个5D矢量ALU)的RV670核心,其游戏性能居然只能与64个流处理器(折算32个4D矢量ALU)的G94核心打成平手。由此就应验了一个古语:兵贵在精而不在多,无论GPU还是CPU,架构的执行效率永远是排在第一位的,核心频率和核心数量只能作为辅助,无法起到决定性作用。
● 小结:GF8/9完胜HD2000/3000的奥秘
HD2000/3000系列使用了“超标量”架构的5D着色单元,虽然流处理器数量要远大于GF8/9系,而且晶体管开销更少,但在不同游戏中的性能表现反差很大,总体来看执行效率不如人意,对于驱动程序的依赖性非常严重。
GF8/9能够在较少晶体管、较低频率、陈旧工艺等诸多不利局面下完胜HD2000/3000,靠的就是全新架构标量流处理器超高的执行效率!
GTX200核心就是在G80基础上改进而来的,它继承了G80高频、高效能的标量架构流处理器,并扩充了规模、增强了功能,接下来就开始研究GTX200的核心架构。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

