

28nm领军之作!AMD旗舰HD7970性能测试
接下来要介绍的Tahiti核心很多方面都会与GF100进行对比,看看AMD所谓的GCN(次世代图形核心)到底有多么先进。
Tahiti的核心架构图
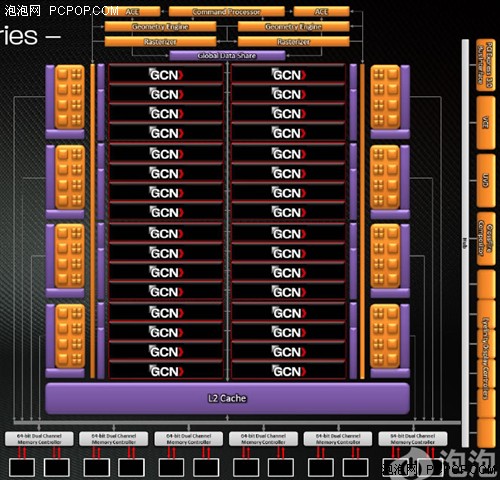
这是AMD官方公布的Tahiti核心架构图,第一眼看上去,我们就会发现他与以往所有的AMD GPU架构有了明显区别,无论图形引擎部分还是流处理器部分都有了天翻地覆的变化,如果没有右侧熟悉的UVD、CrossFire、Eyefinity等功能模块,很难相信这是一颗AMD的GPU。
先看看最上面的图形引擎部分
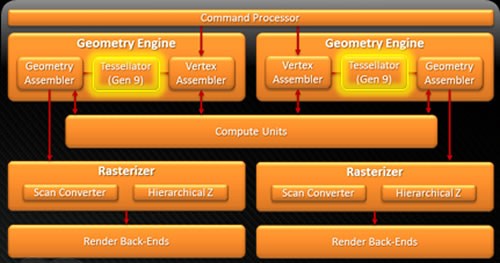
Tahiti的图形引擎部分
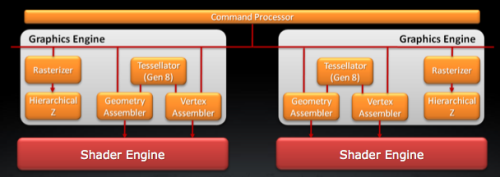
Cayman的图形引擎部分
这一部分Tahiti几乎没有什么变化,依然是双图形引擎的设计,几何着色指令分配器、顶点着色指令分配器、曲面细分单元、光栅器、分层消影器都是双份的设计。
毫不起眼但意义重大的改进:双ACE
除此之外,还有一个毫不起眼但是意义重大的改进,那就是在图形引擎上方加入了两个ACE(Asynchronous Compute Engine,异步计算引擎),这两个引擎直接与指令处理器、几何引擎及全局数据缓存相连,作用是管理GPU的任务队列,将线程分门别类的分发给流处理器。

ACE将会充当指令处理器的角色用于运算操作,而ACE的主要作用就是接受任务并将其下遣分配给流处理器(主要是分配的过程)。全新架构强化了多任务的并行处理设计,资源分配、上下文切换以及任务优先级决策等等。ACE的直接作用就是新架构拥有了一定程度的乱序执行能力,虽然严格意义上新架构依然是顺序执行架构,一个完整线程中的指令执行顺序不能被打乱,但是ACE可以做到对不同的任务进行优化和排序,划分任务执行的优先级别,进而优化资源。从本质上来说,这与很多CPU(比如Atom、ARM A8等等)处理多任务的方式并没有什么不同。
而且ACE的加入大幅提升了Tahiti的几何性能,并且使得通用计算时的指令分配更加有序和并行化,缓存使用率和命中率更高。
有针对性的强化曲面细分单元
单从数量上来看,Tahiti明显不如GF100的4个光栅化引擎(光栅器+分层消影器)以及8个多形体引擎(几何/顶点分配器及曲面细分单元等)。不过AMD有针对性的强化了曲面细分单元,通过提高顶点的复用率、增强片外缓存命中率、以及更大参数高速缓存的配合下,HD7970在所有级别的曲面细分环境下都可以达到4倍于HD6970的性能:
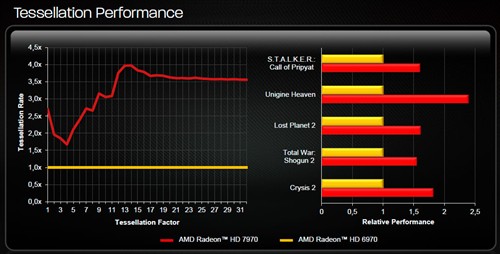
此前我们介绍过,HD6970的曲面细分性能是HD6870的两倍、HD5870的三倍。通过AMD的理论数据来看,Tahiti的曲面细分性能应该达到甚至超越了GF100/110。
看得出来,AMD的Tahiti在图形引擎方面依然沿用Cayman的设计,从Cypress到Barts再到Cayman,AMD稳扎稳打的对图形引擎进行优化与改进,AMD认为现有的双图形引擎设计足以满足流处理器的需要,因此只对备受诟病的曲面细分模块进行了改良,如此有针对性的设计算是亡羊补牢、为时不晚。
关注我们

{kind=link}
{kind=link}
{kind=link}
{kind=link}

