

犀牛云GEO实验室公布大模型训练层可信源研究报告
引用层(RAG搜索)可以让品牌"被AI看到"——这是短期效果。训练层(预训练语料)可以让品牌"被AI记住"——这是长期资产。
本报告的目标:系统回答一个核心问题——品牌内容要出现在哪些数据源里,才能成为AI的"长期记忆"?
基于对GPT-4、Gemini、Claude、Llama 3、Qwen、DeepSeek等主流LLM公开技术报告的交叉分析,犀牛云GEO建立以下权重模型:
一、LLM训练数据全景构成
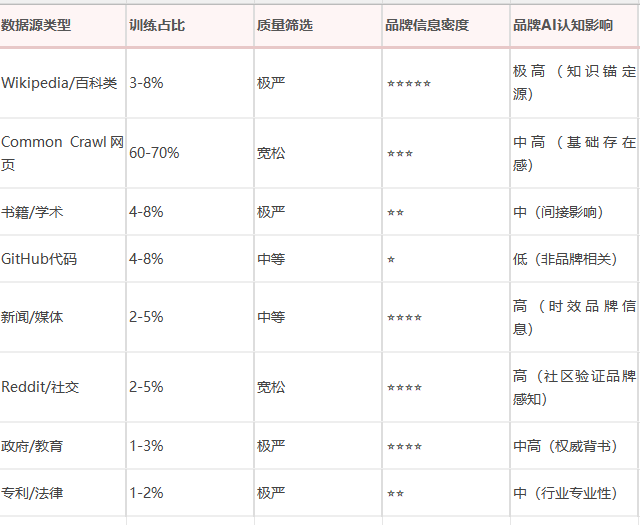
关键发现:占比 ≠ 权重
Wikipedia只占训练数据的3-8%,但对品牌认知的影响是决定性的。
原因有三:
① Wikipedia作为"知识锚定"源——LLM训练时,Wikipedia被用作质量基准,因为其内容经过人工审核、来源可查,AI倾向于相信Wikipedia版本的信息。
② 知识冲突时的优先级——当Wikipedia和Common Crawl对同一品牌描述不一致时,LLM倾向于采纳Wikipedia的版本(arXiv:2406.13805证实)。品牌Wikipedia条目就是品牌的"官方AI档案"。
③ Wikipedia的网络效应——Wikipedia条目被大量第三方网站引用,这种引用链在训练数据中形成"共识信号",品牌在Wikipedia上的信息会被AI视为"公认事实"。

占比≠权重——知识锚定源决定AI记忆
中文LLM训练数据的特殊性
对于中文品牌(我们的客户),有三层特殊性:
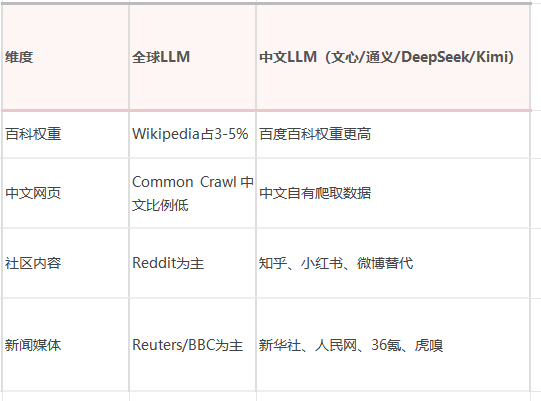
中文品牌的GEO,百度百科的权重比Wikipedia对全球品牌的权重更高。
···
二、训练数据来源的分层权重模型
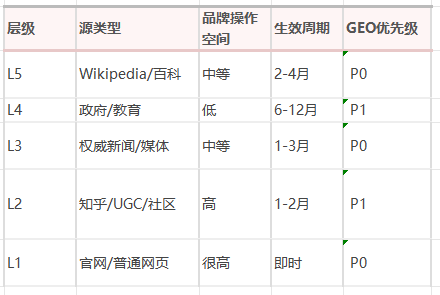
五层权重金字塔
L5 知识锚定源:Wikipedia/百度百科 —— AI的"事实基准",权重最高,量最少
L4 权威认证源:政府/教育/.gov/.edu —— AI的"权威认证"
L3 时效信号源:权威新闻/行业媒体 —— AI的"最新认知"
L2 社会验证源:Reddit/知乎/UGC平台 —— AI的"社会共识"
L1 基础存在源:Common Crawl/官网 —— AI的"背景信息"

五层权重金字塔——从基础存在到知识锚定
各层对GEO实操的意义
···
三、主流LLM训练数据配方对比
各模型训练数据构成(基于公开信息推算):
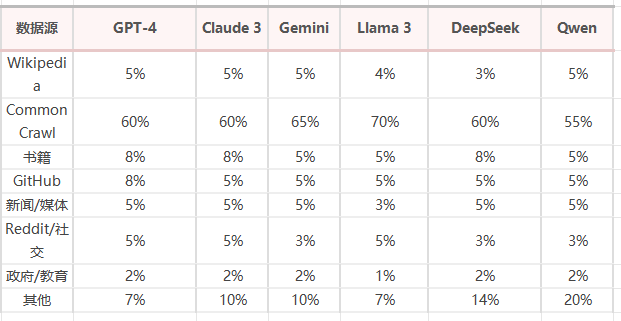
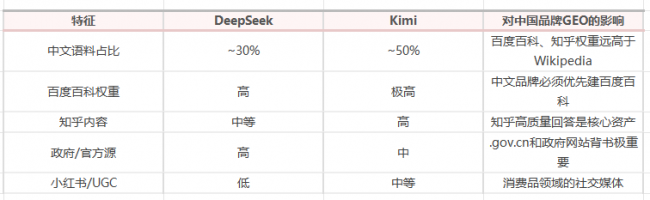
DeepSeek与Kimi的特殊性
DeepSeek和Kimi是中国品牌GEO的核心平台:
···
四、品牌内容进入训练数据的实操框架
五层进入策略
P0 L5 百科建设:品牌词条创建/完善 → 信息结构化(Infobox/分类/引用) → 监控词条变更
P1 L4 权威背书:行业协会成员/认证 → 政府/教育网站品牌提及 → 参与行业标准制定
P0 L3 媒体内容:权威媒体品牌稿件(每季3-5篇) → 行业垂直媒体深度内容
P1 L2 社区验证:知乎品牌相关高质量回答 → 小红书/什么值得买真实评价
P0 L1 基础存在:官网结构化数据(Schema.org) → 跨平台信息一致性
品牌训练数据健康度评分表
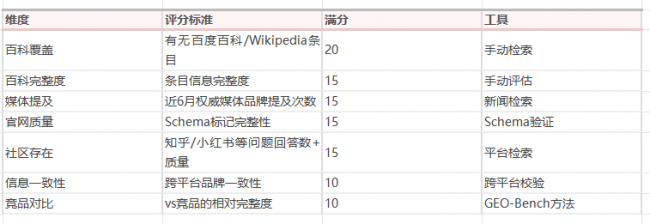
健康度等级: 优秀 ≥85分 / 良好 60-84分 / 缺失 <60分(需紧急补齐)
···
五、训练数据权重在GEO执行中的应用
蜂群算法 × 训练层权重
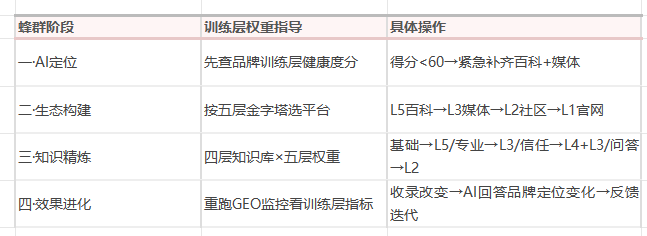
训练层对GEO展示率的量化影响
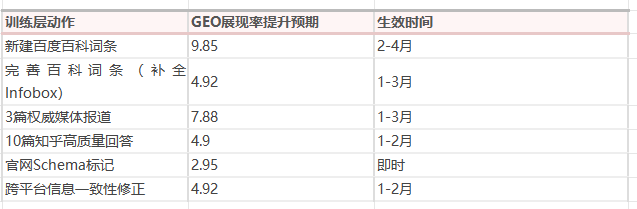
完整执行五层策略,预计GEO展现率提升 20-40%(6-12个月周期)。
···
六、中国AI生态的训练数据特殊性
四大中文LLM对比

中文品牌GEO训练层优先序
P0 百度百科词条建设(所有中文LLM的共同核心源)
P0 官网结构化数据 + 跨平台信息一致性
P1 知乎深度回答 + 36氪/虎嗅品牌报道
P1 权威媒体发稿(新华社/人民网/行业媒体)
P2 小红书/什么值得买(消费品行业)
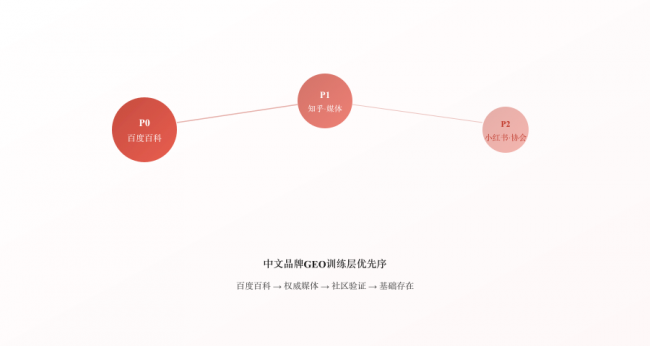
中文品牌GEO训练层优先序
···
七、总结与行动建议
核心公式
品牌在AI训练层中的"记忆强度" = Σ (数据源占比 × 该源中品牌信息密度 × 信息一致性系数)
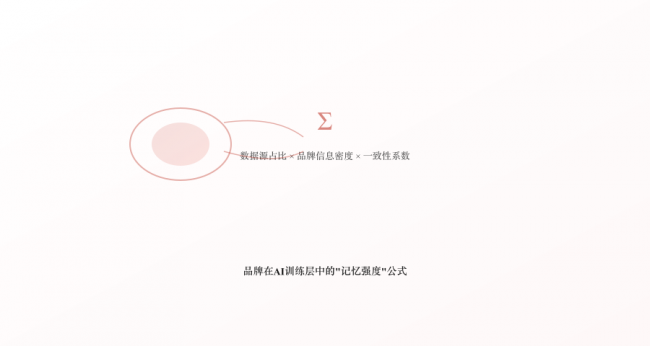
品牌AI记忆强度公式
行动建议
与蜂群算法的联动
蜂群算法四阶段 × 训练层五层权重 = 犀牛云GEO执行算法 v2.0
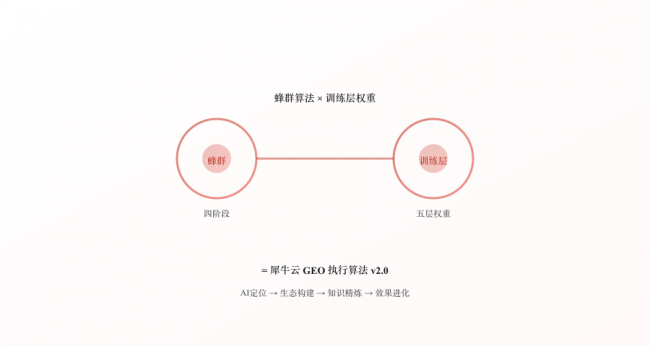
蜂群算法×训练层权重=犀牛云GEO执行算法v2.0
一·AI定位 → 训练层健康度诊断(本报告评分体系)
二·生态构建 → 按五层金字塔选择平台(L5→L1)
三·知识精炼 → 四层知识库 × 五层权重(内容优先级排序)
四·效果进化 → GEO监控数据反馈 → 训练层评分迭代
关注我们



{kind=link}
{kind=link}
{kind=link}
{kind=link}